Data exploration is an important step of Data modelisation and Machine Learning projects lifecycle. Even if not needed for supervised modelisation, as algorithm are now powerful enough to build the best model without human insight, Data Exploration may be useful when starting the project :
to check data quality and integrity ( even if “no data” is still an important insight )
to check modelisation feasibility with visual hint
and, more important, to onboard the line of business user and formalize intuition and goal of the project !
The last point is probably the most important. In every Datascience project, first and most important step is to define clear objective that serve purpose. Exploring data with visual tools oftent allow to get insight from business expert and get them involved in the project
We define data exploration as any process that take raw data and produce indicators and charts for human to analyse. Statistics is a kind of data exploration. Scatter plot and histogram are an other kind.
Sometimes, Humans can build very basic models from statistical indicators and get rules-based model like if age > 40 then wants_motobike = true.
In a Machine Learning project pipeline, Data exploration may serve the 3 following purpose.
Before any modelisation, the first step of any machine learning is , or at least, should be, data exploration.
Before Big Data and Machine Learning advent, most of data analysis where done visually with and data Insight were extracted by human from statistical indicator and charts.
Data Analysis is getting replaced with Artificial Intelligence and Machine Learning for understanding phenomena and building models but human mind is still great at getting insight from visual clue.
Exploring data may still help to build the target, decide modelisation type or find an innovative feature engineering. Sometimes it serves to detect underrepresented category and add some weigh to the the data.
Warning
Do not build segment for Machine Learning and AI problems ! Segmentation was a great way to build basic models but Big Data and Machine Learning tools do not need Segmentation anymore as they works on individual sample. Only use segmentation to build basic rules-based model or explore data and understand problem. But if the project need performance, use supervised learning of IA unsupervised technics.
Even if building a model only from data exploration is not the best way to get performance, data exploration can serve as a show stopper as it can highlight two main issue from your data before going on the modelisation step :
random or noisy data
unbalanced data
There are specific indicators for noisy data or signal/noise ratio and this can be seen from some specific visual representation. Looking after a too low signal/noise ratio is a good way to avoid poor modelisation due to poor data quality.
About unbalanced data, it’s still possible to get good models if the low rate target has some very specific features , wich will probably appear in the data exploration process, but as a rule of thumbs, looking for general shape of data and some under-representation of sur-representation for planning some kind of weighting is considered as good practice.
Most important output of running data exploration, especially with visual tools, is to onboard the line of business manager into the datascience project.
Success for a datascience project often rely on building the good target, that serves a true business purpose. By running a data exploration phase with someone from the business, you can, as Data Scientist Practitionner :
get insight to build your metrics and objectives , and thus optimize the model for R.O.I
get the Lob manager involved and build a relationship to build the fittest model for business.
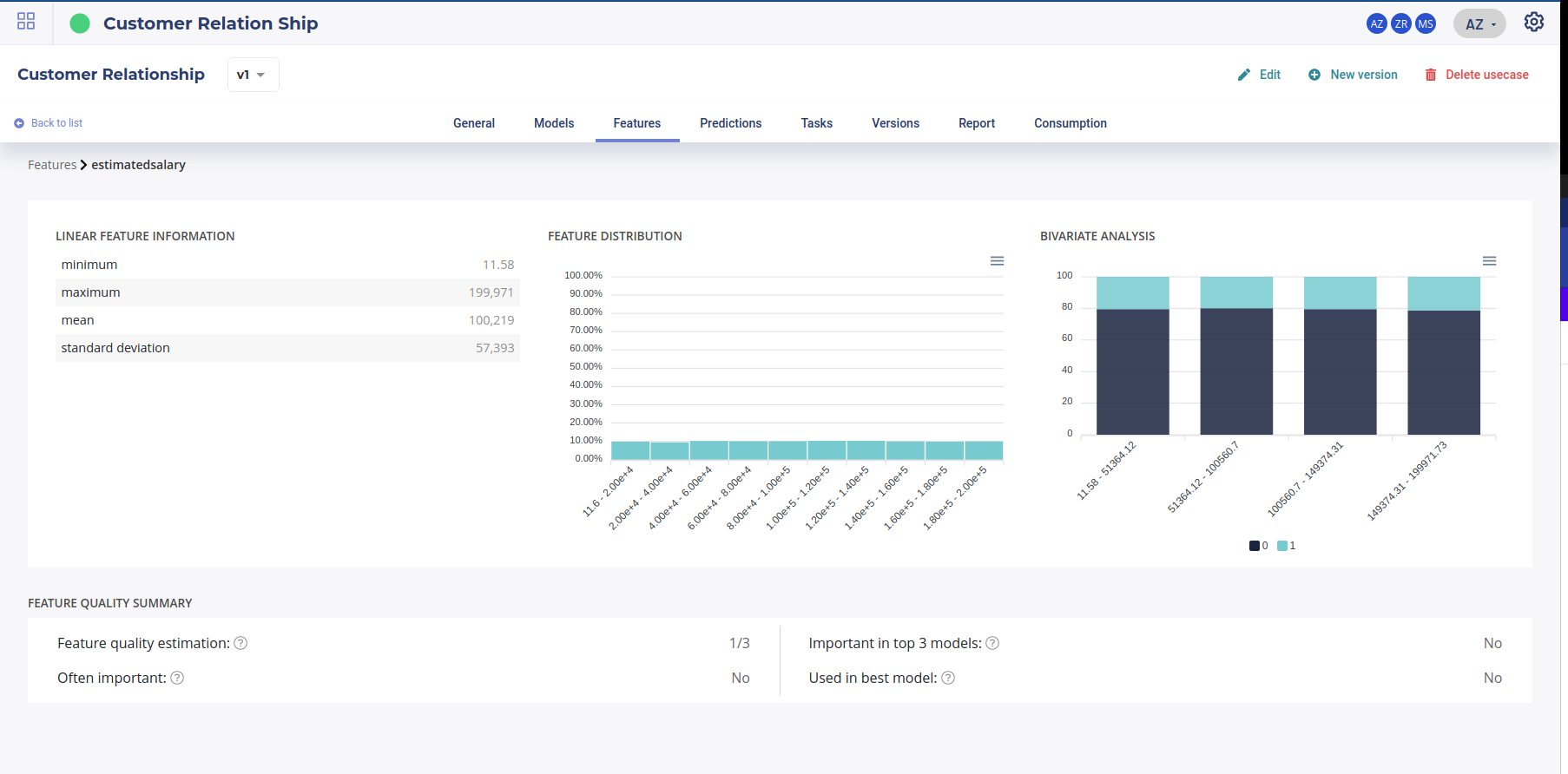
Statistics available on experiment only ( note the bivariate analysis related to the target )¶
or
Home>[myproject]>[mydataset]>General
Statistics available on each new dataset ( automatic computing )¶
Note
Some statistics and chart are built only once the use case ( see Experiments ) has been defined because bivariate chart related to the target are built. Some others are available few seconds after you created new Data
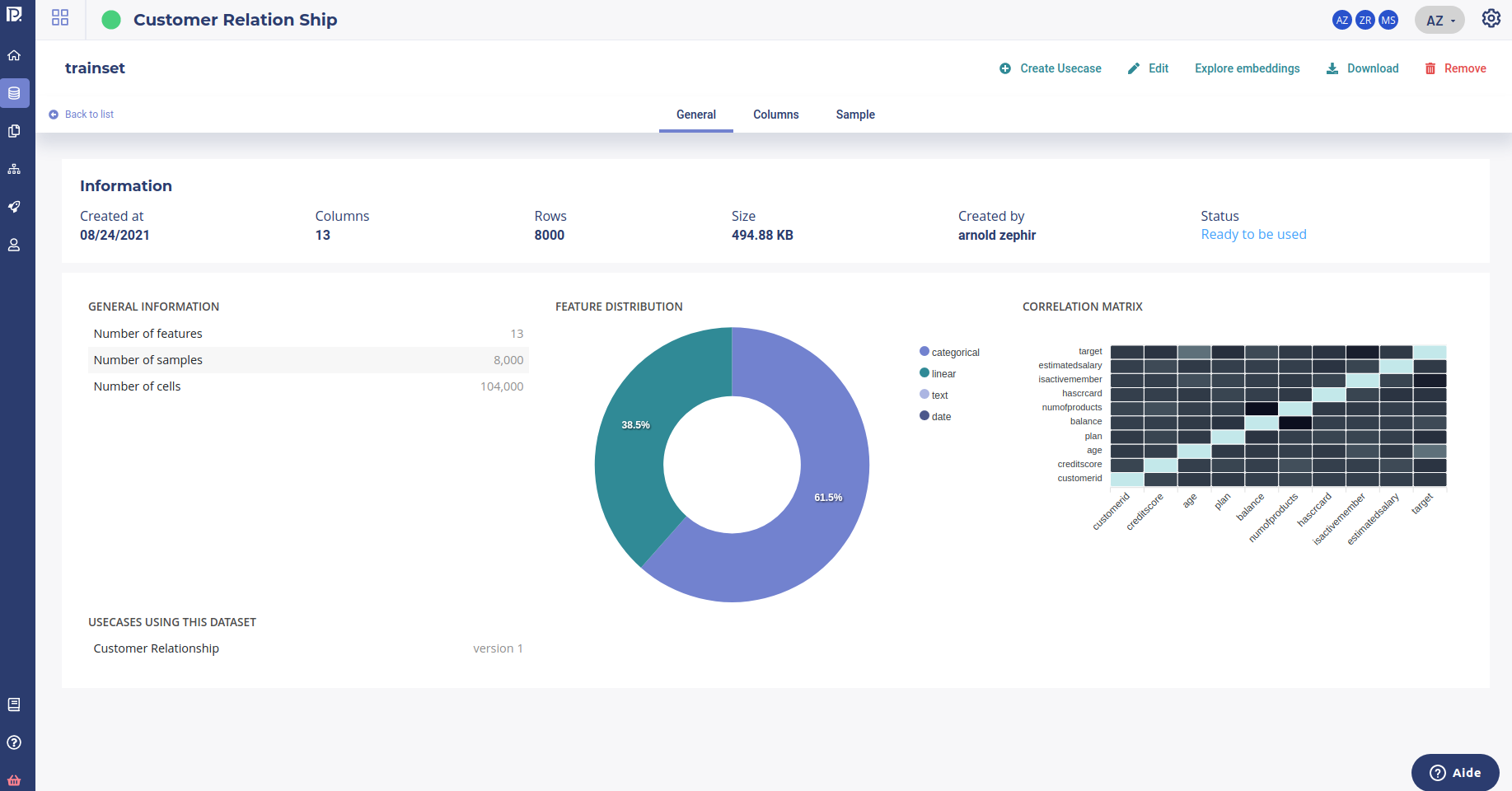
Basic statistical indicators help to better understand the dataset yet more powerful technics and tools exist based on continous vector built upon the data.
Embedding technics are various way to transform data such that you go from a discrete ( categorical and such ) representation of data to a continous one with mathematical vectors. It is a very important method as it allow to run mathematical operations on all kind of data ( cosine similarity, difference, addition ) while preserving relationship between features.
When embedding data, each sample of the dataset is transformed into a vector with fewer dimensions. This vector may be used to build chart, compute similarities between sample, cluster data or detect outliers.
Note
Four usage of Data Embedding :
visualize cluster
compute similarities between sample
detect outliers
visualize segment relative weights
There are many technics to build embedding but here are the most common
PCA ( Principal Common Analysis ) is based on Matrix eigen vector and eigen values. When applied on a dataset, it find eigen values and eigen vector of the data and resulting vectors can be interpreted as “axes of greater variance”. It often put emphasis on feature correlation and is used as a dimension reduction algorithm
Note
Let’s say that you got a dataset with 10 samples of 5 features
X1
X2
X3
X4
X5
fr
43
10
50
5
fr
43
4
20
3
en
13
7
35
3.5
en
12
20
100
10
en
12
34
170
17
en
13
18
90
9
fr
41
18
90
9
en
12
20
100
10
fr
43
32
160
16
fr
43
64
320
32
Even if there are 5 features, a PCA wil show that the samples are in fact variation of 2 vectors :
a first one highly correlated with (X1,X2) features
another one correlated with (X3,X4,X5)
Thus this 10 sample may in fact be written as two dimensionnal features :
V1
V2
0
0.1562
0
0.0625
1
0.1094
1
0.3125
1
0.5312
1
0.2813
0
0.2813
1
0.3125
0
0.5
0
1
Where :
X1 = “fr” if V1 == 0 else “en”
X2 = -30*V1 + 43
and
X3 = 64*V1
X4 = 320*V1
X5 = 32*V1
PCA may be used as some kind of feature importante
Variationnal Auto Encoding is a more powerful technic trying to compress data with less features that the original dataset. For example, if a dataset has 300 features but the compression algorithm can built a dataset with 30 features that is able to reconstruct the original dataset without losing too many signal, the theory says that the analysis can be done on the 30 features without loss of meaning or signifiance.
Variationnal Auto Encoding often use a Neural Network that is tasked to generate to output the vector presented in input but with few neurons ( for example, only 4 ).
The signal in the deep layer of this Network may be interpreted as a vector representation of the sample, call embedding, and has the interesting property that you can build a distance metric such that similar samples have a small metric distance.
Given this property you can build your analysis on the embedding space.
This is this technology that Prevision.io platform uses for data exploration
The “Compute Embeddings” button is available in the Data section of the platform. When you Upload or import a new dataset, it becomes available when the data importation is done.
As this is a cpu intensive algorithm, user must explicitly launch it by clicking on the button. It lasts about a few minutes and once done, you can explore your data with the “Explore Embeddings” button.
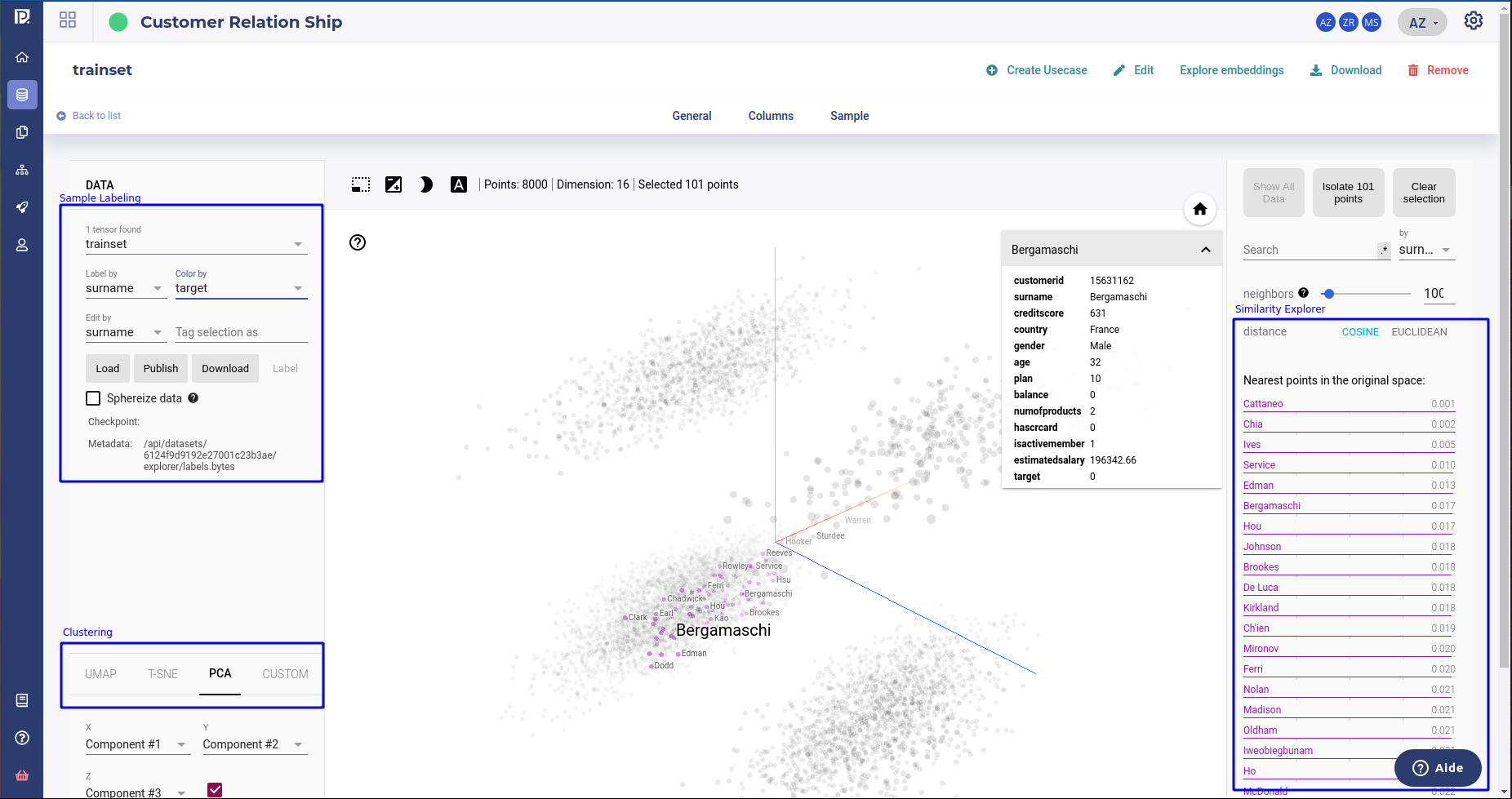
The data explorer. Draw embedding vector on a 3D charts¶
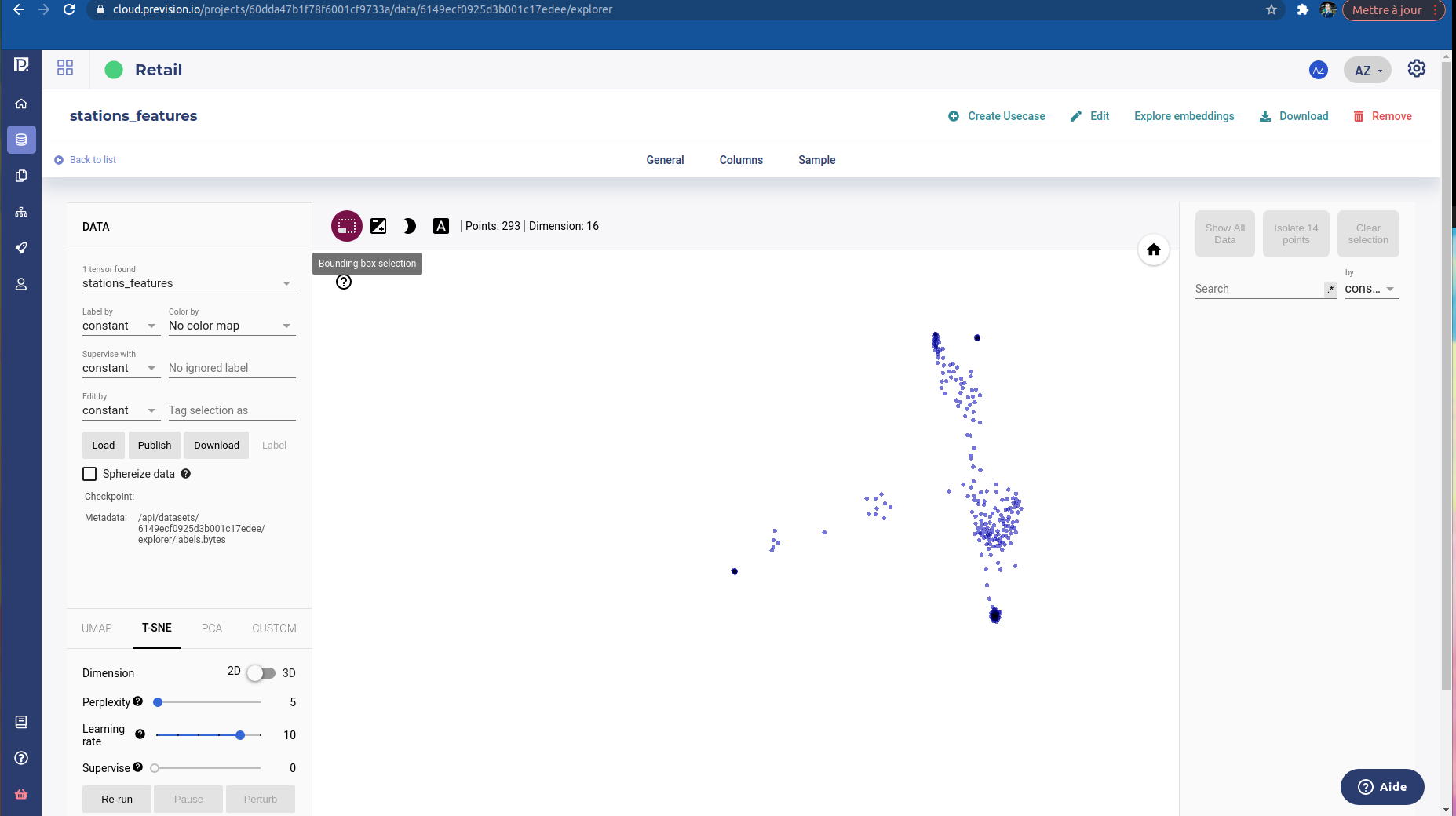
The data explorer is an interface to handle data rows embedding, or at least a subsample (5000) of it. It projects the data onto a 3D or 2D vector space and give some tools for exploring data :
the search and similarity sidebar, on the left, displays nearest neighboors for 2 metrics, cosine similarities and Euclidean distance, when clicking on a point. The number of nearest neighboors is a parameters that user can change. Note that you can isolate a point and its neighboors for further investigation
the labeling box on the top left corner allows to assign labels and color to sample along some feature. You can display modalities ( or values ) of features as a label or as a color.
the clustering box on the bottom left let user launch a clustering :
PCA : fastest but do not respect distance
TSNE : better but slow and complex to use
UMAP : less good than TSNE in respecting distance but fastest and a little bit easier to use
The central window displays a navigatio interface when you can pan, rotate and zoom.
To build cluster, and segment, you just need to launch a clustering computing by using the clustering section. There are 3 methods of ‘clustering’ :
PCA
TSNE
UMAP
Each methods has its own set of parameters that build cluster more or less constrained.
Note
This are not methods of clustering per se as the clustering algorithms assigns a class ( cluster number ) to each point of the dataset. Here are algorithm that visually bring together data rows that share similarities ( ake whom distances are small ). It allows visual inspection by a human mind, which is is often better to make generalities than algorithm.
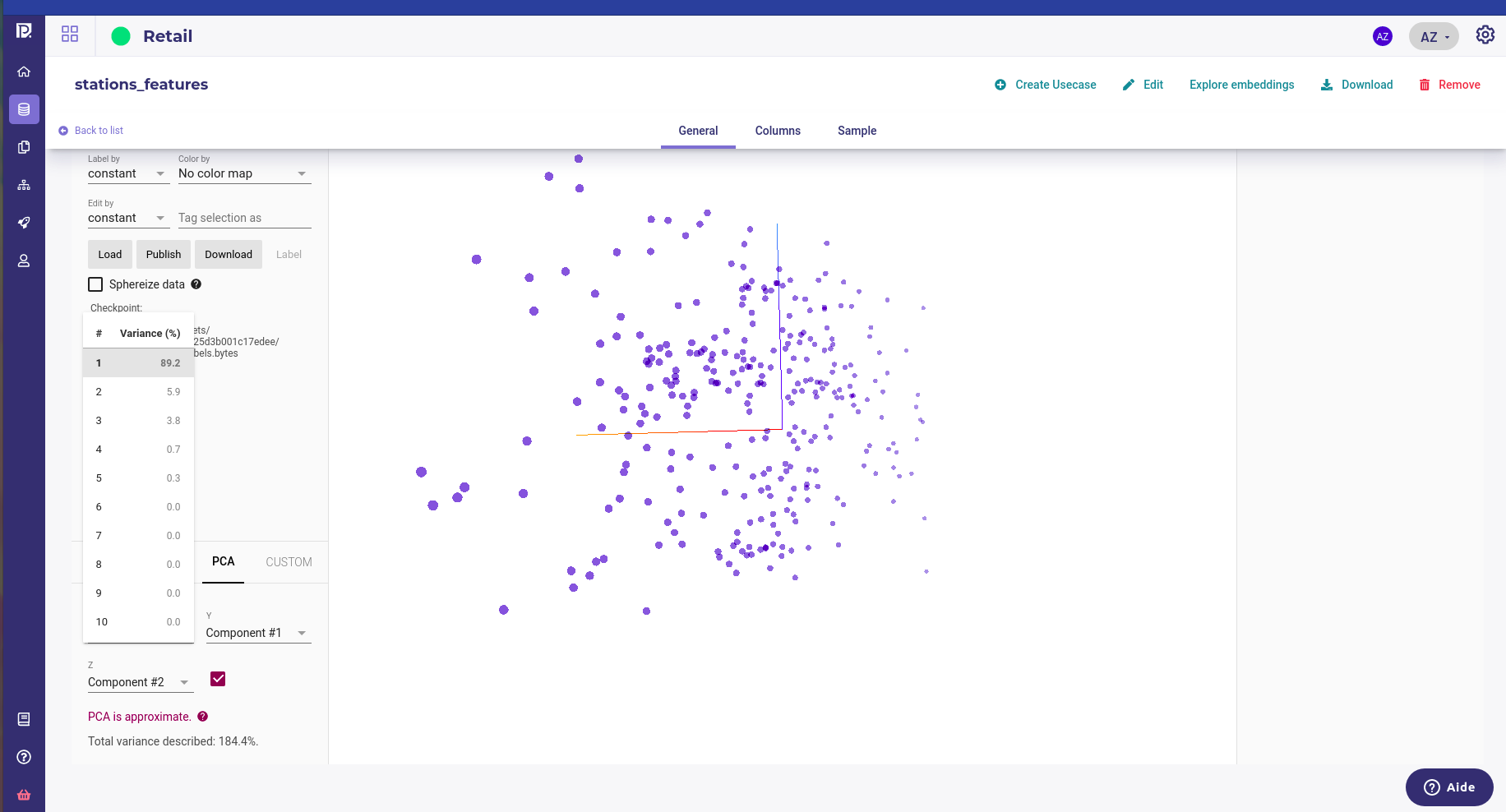
PCA is a very cheap method but fast to compute. It sometimes highlights very simple variance axes and give some insight but do not expect much. The interesting thing in PCA algorithm is that it computes the explained variance for each component :
Thus, you can quickly see if your data has in fact a low dimensionnality.
On the example above, we see that one component hold 89% of the data variance so even if the original dataset has 428 features, there seem to share a lot of information.
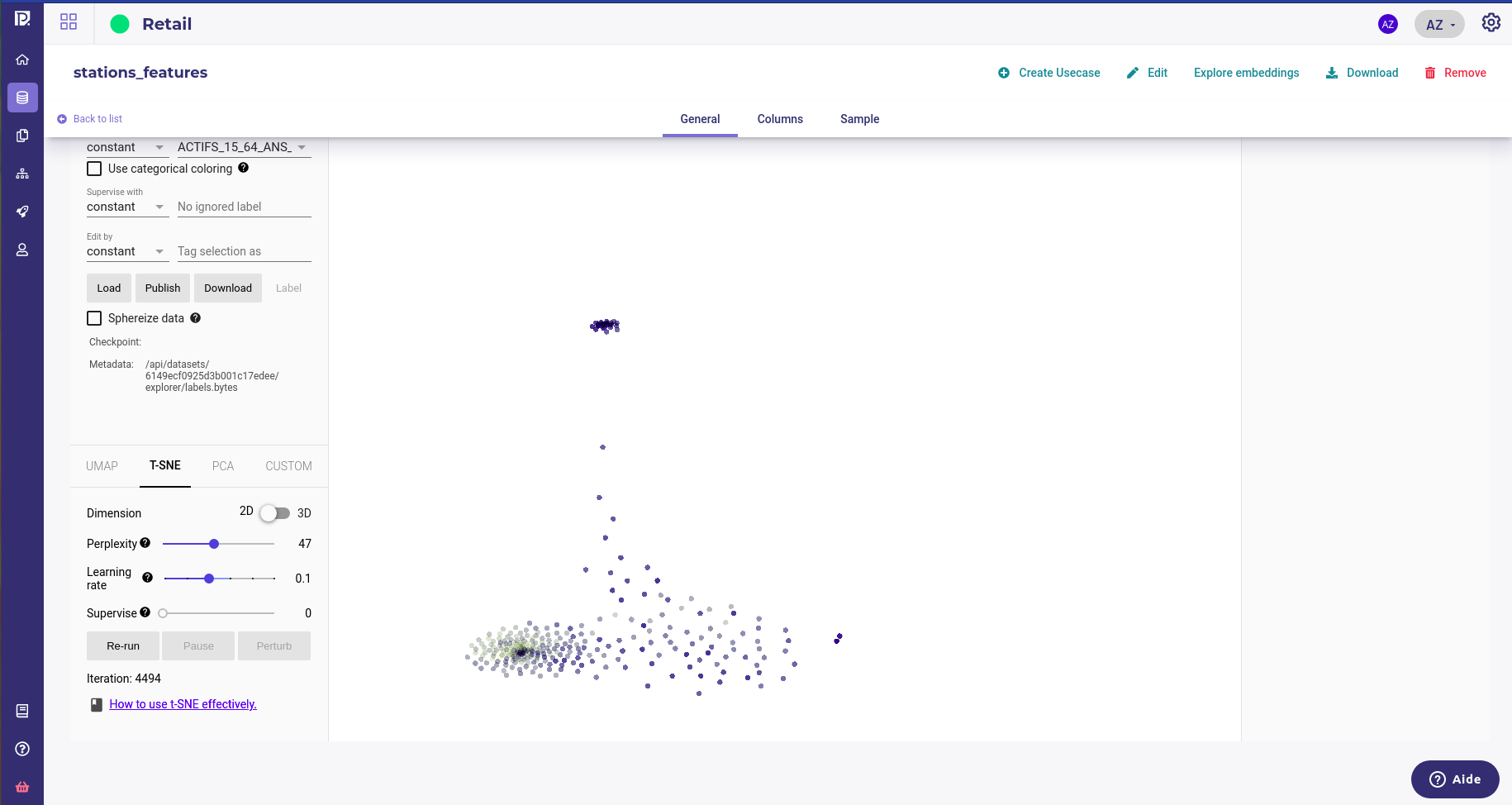
TSNE is the most interesting clustering method as it can lead to very defined, and separated, segment when they exists. Yet it can be quite long to compute and hard to tune.
As a rule of thumb :
the higher the perplexity, the more defined the shape but the longer to converge.
with a smaller learning rate, convergence takes longer but point are well placed
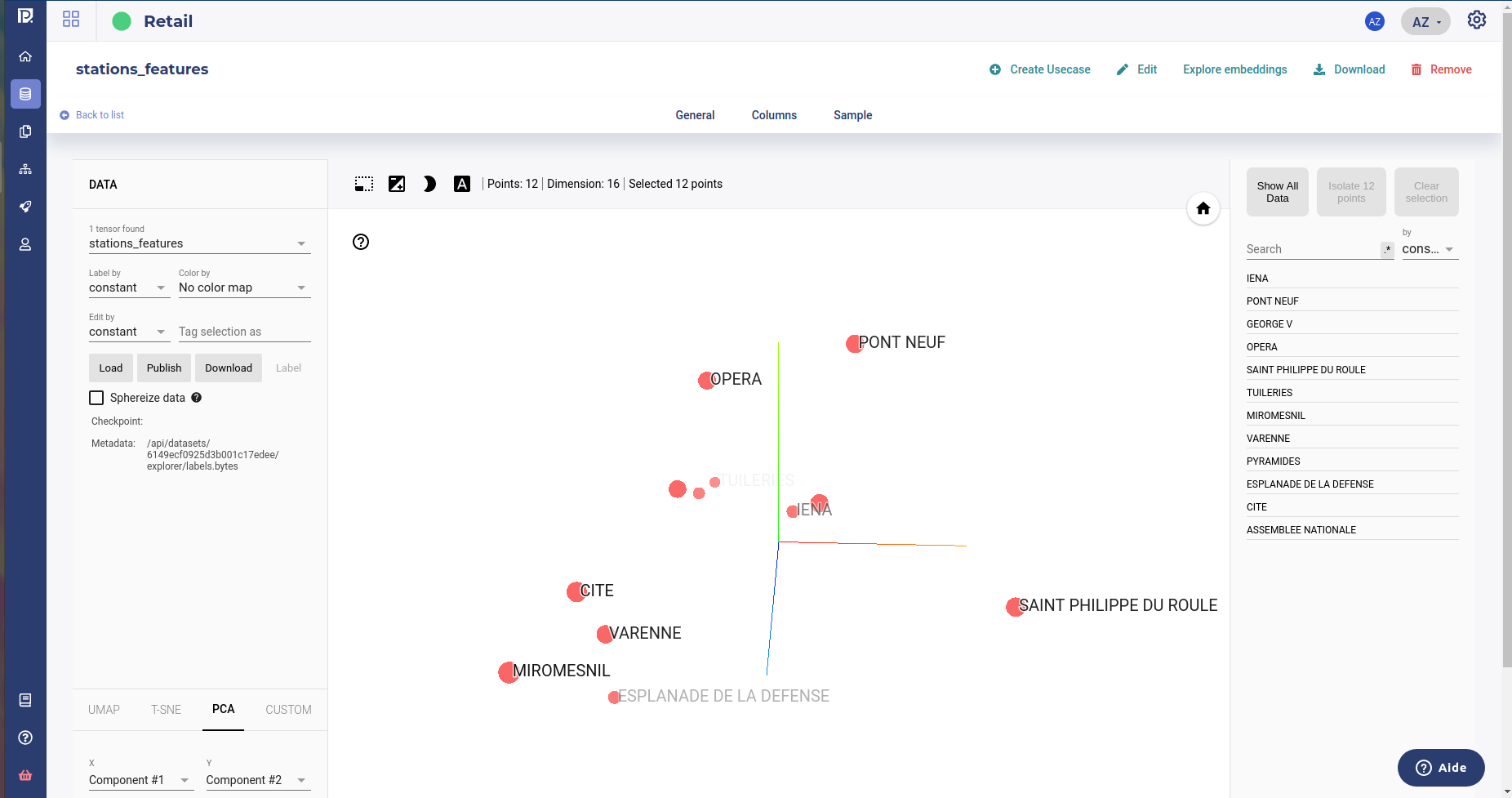
Clear cluster of Paris Subway station ( residential, job and tourism )¶
Note that you can constreint cluster to a feature, to force the algorithm to split the cluster along this features but do it only if you want to confirm some intuition.
UMAP is way faster thant TSNE and get good result to put most similar point together but is less able to generate well blocked shape. Yet, it’s often good to use it to start exploration and then switch to tsne to validate some hypothesis.
UMAP has only one parameter, that is number of Neighbors. The more neighbors you allow, the larger and more inclusive are the structure of cluster.
Once you got some visual cluster, it’s time to explore points and their similarities but let’s talk about similarities, distance and proximity in 3D spaces.
Note
As we said before, the algorithms used by Prevision build vector space where you can build distances metrics such that similar sample have a small distance.
Yet, in most of case, the list of similar points displayed on the right will not always be grouped together on the central window after a clustering run because the visual explorer is only 2D or 3D.
Similarities distance , cosine similarity or Euclidean distance, are computed on the whole dimension of the embedding space as UMAP and TSNE are computed so that similar points are near together in the 2D/3D space. Yet is not always possible to respect every constraints and sometimes, some points with a small distance wil be far in the 3D space.
When it happens, always keep the similarities distance as the truth.
Explore sample and look after similarities between samples¶
Whatever the representation you used, PCA, TSNE or UMap, you can always click on a point, which represent a row of your dataset.
When you click on a point :
its features are displayed in a small dropdown windows
a set of similar samples are highlighted and displayed on the similarities windows on the right sidebar.
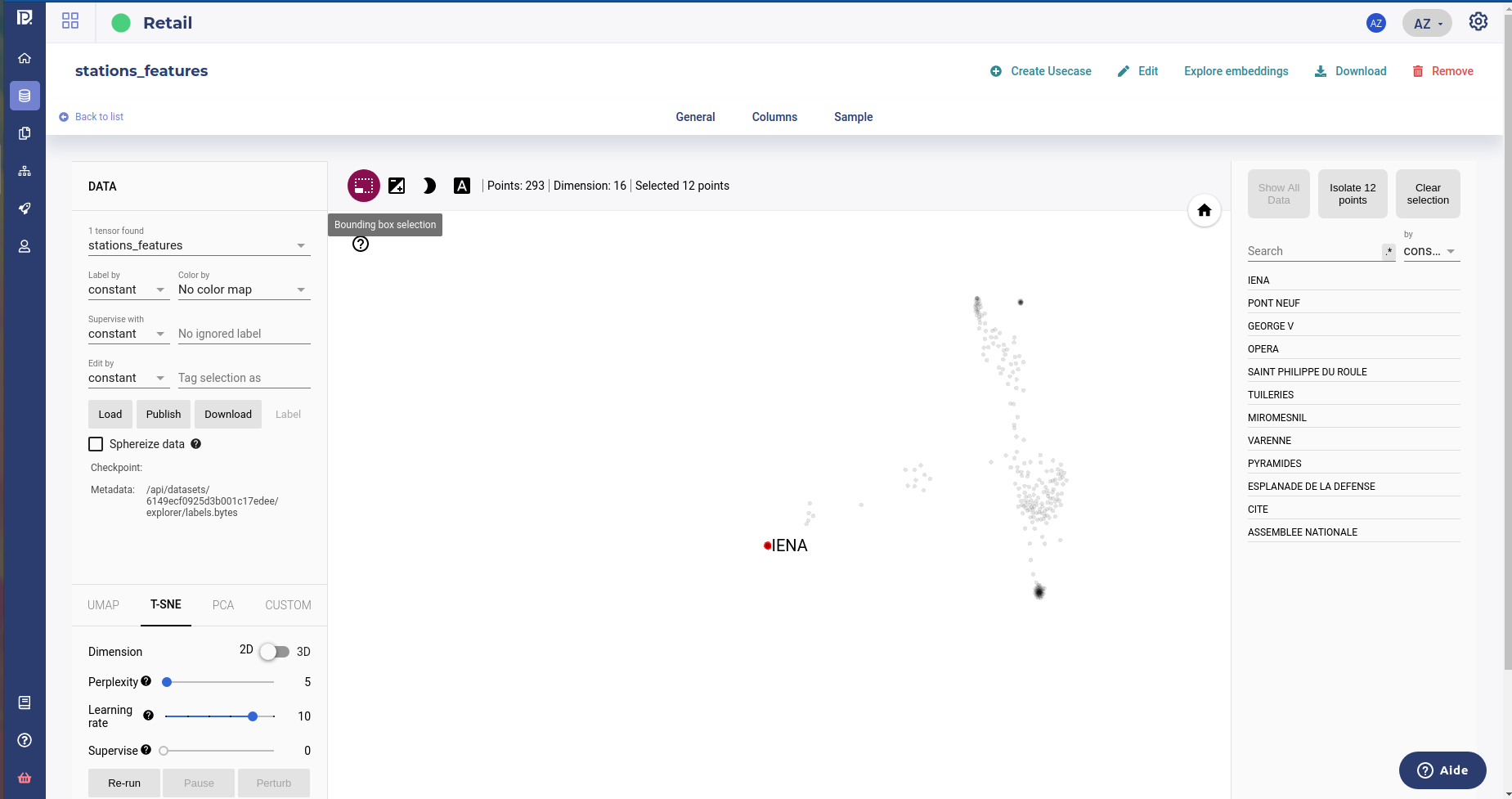
In this window you can :
select the number of neighboors displayed
change the distance used, cosine ( dot product ) or euclidean distance
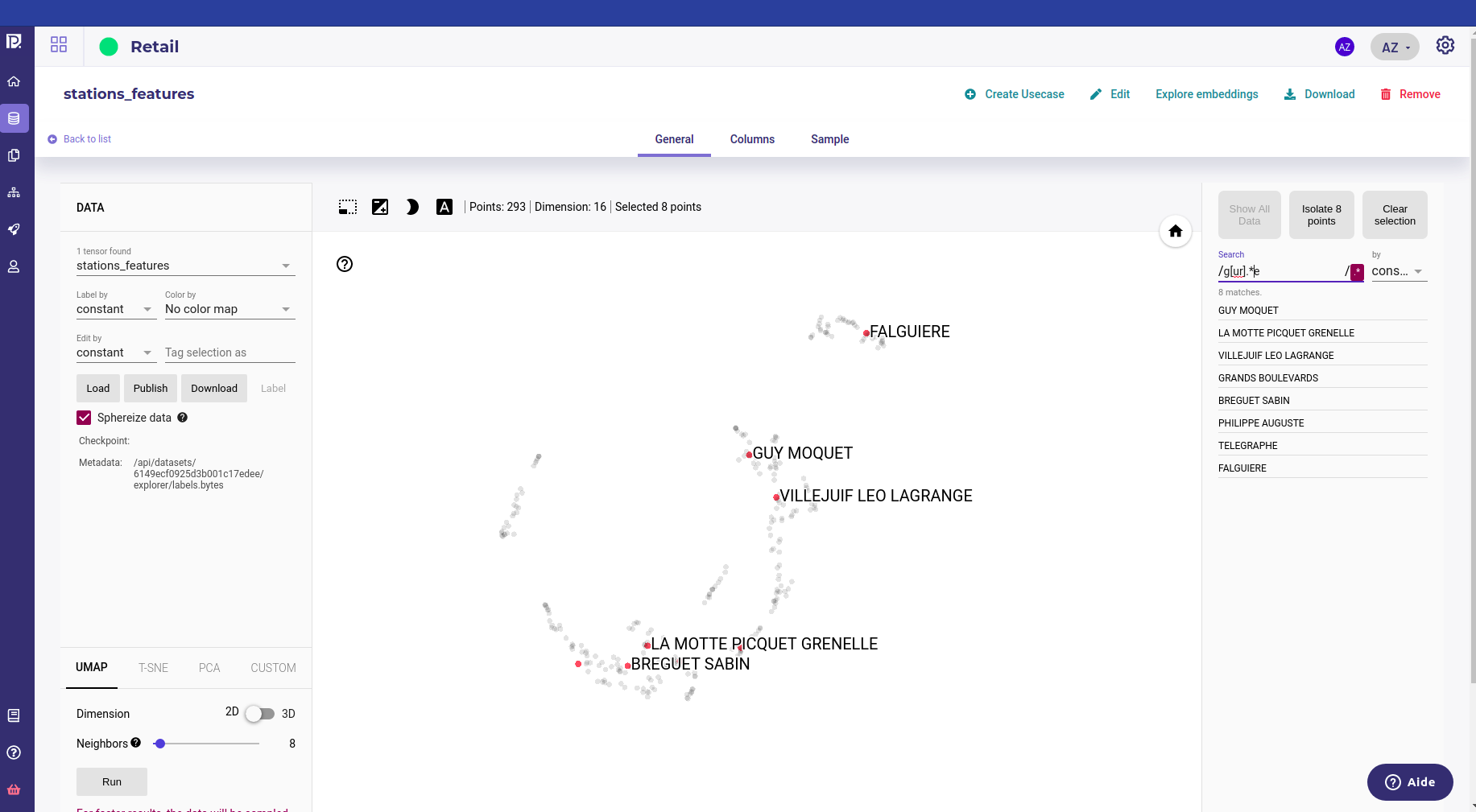
search and highlight for specific value on specific feature ( Note : you can use regexp for filters )
filtering all the station whom name match g[ur].*e¶
isolate for analysis all the highlighted points
clear the selection
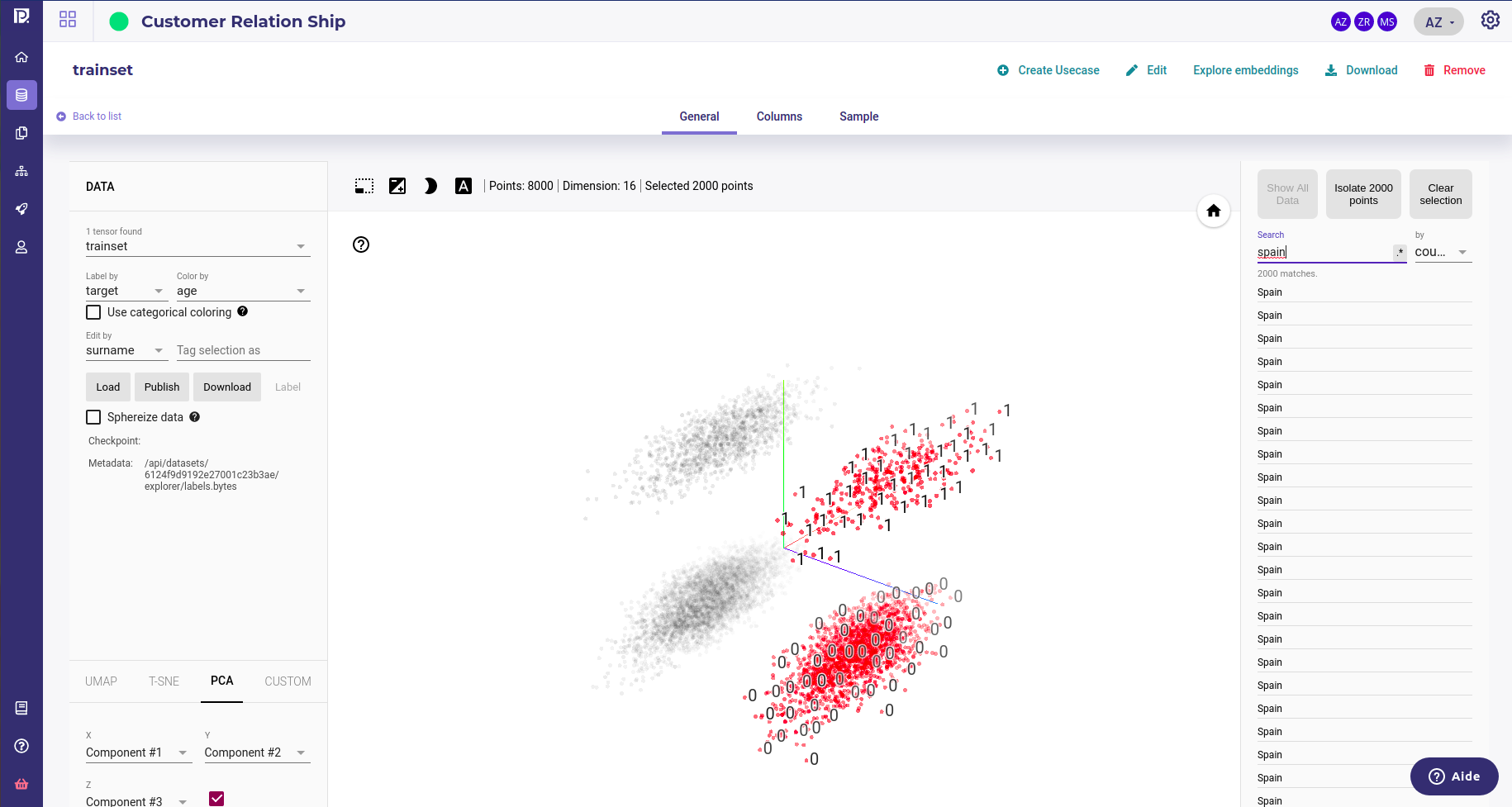
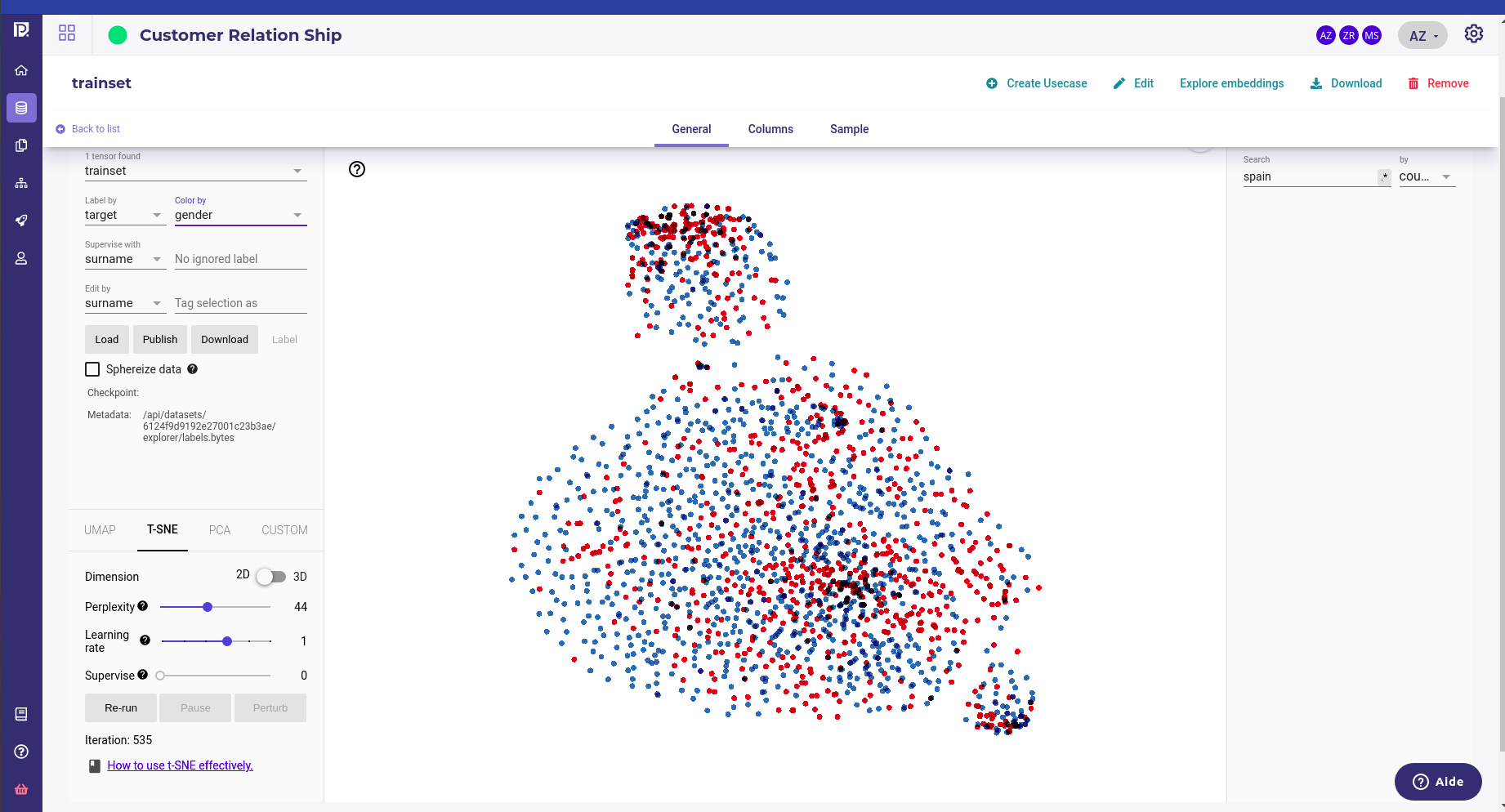
In this dataset exploration, user has highlighted all the customers from Spain and siplay the target.¶
Once you have isolated some sample, the cluster then run only on this selection, allowing to target your analysis on a specific segment. Thanks to the sample labeling box on the left you can label and color your sample along a feature.
The spanish user have been isolated and a cluster ran on this segment only. The gender is used has coloring showing that gender is not a main concer in churner split¶
One of the positive byproduct of Embedding technics is that you can easily detect outliers visually. As the vector are build so that sample grouped by similar feature distribution and covariance, points that are visually outside any shape can be interpreted as outlier.
Using a small perplexity for tsne isolate outliers. You can then click on any point of this outlier group to select it and its neighboors, if some, and then isolate them
Once isolated, you can color or select each point in order to understand why this samples stands out.
Like every feature of Prevision Studio, you can get the embedding over the API .
The embedding are saved as numpy32 float and is an array. From them you can do many things :
rerun your own clustering technics
make histogram and stats along each axes in order to understand the meaning
anything you want
To run the Code below you need :
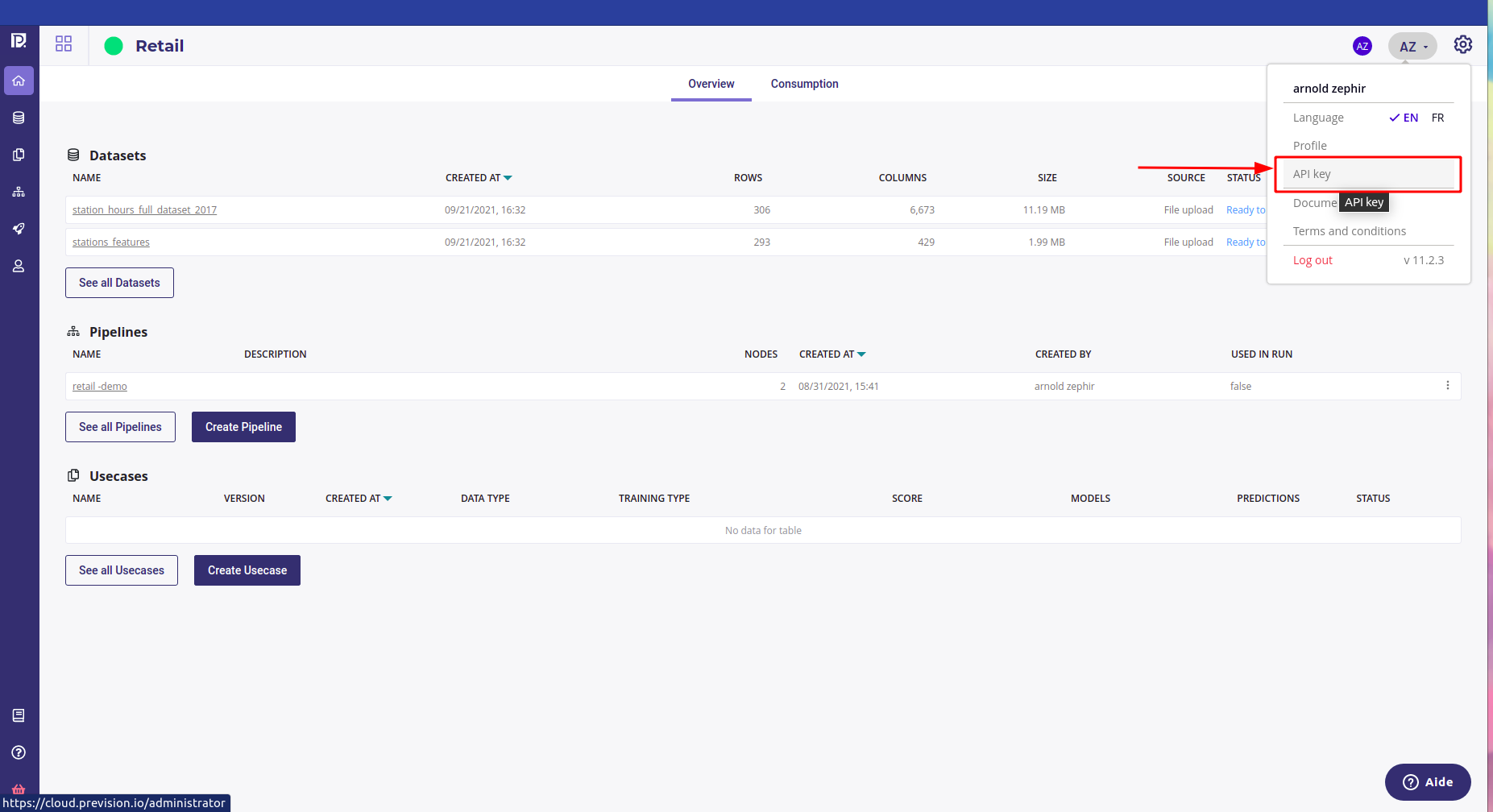
your Master Token. It is available in the API Key page of your user settings :
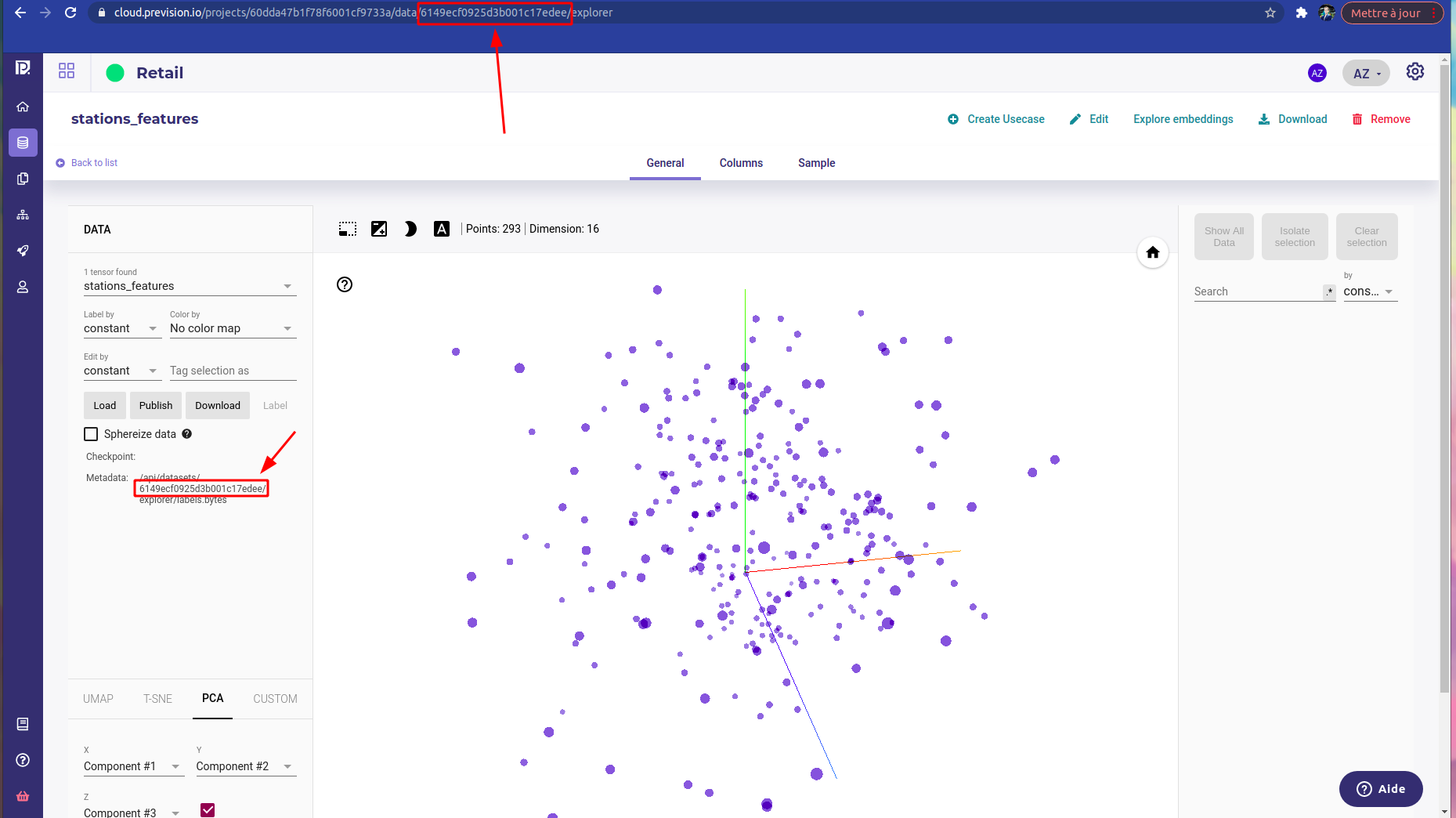
The Id of your dataset embedding, wich is available in the url or in the
You can use the native urllib module to parse API but you need pandas and numpy to use data.
First, import native python 3 urllib.request and set up your Token and url built from dataset id ( warning : if you have an on promise server or custom dedicated domain, you need to replace the url “cloud.prevision.io” with your own )