Experiments¶
Note
An experiment represents a collection of trained Models, that were created either by the AutoML Engine, or from External Model. By Versionning your experiments, you will Evaluate your experiment and compare different models against different metrics with details on predictive power of each Features.
This models may come from the Prevision AutoML engine or be imported in the Project as an External Model.
Any model of your experiments can then be used for Deployments as REST APIs or included in a Pipelines
Regarding the problematic and the data type you have, several training possibilities are available in the platform :
Training type / Data type |
Tabular |
Timeseries |
Images |
Available for External Model ? |
Definition |
Exemple |
|---|---|---|---|---|---|---|
Regression |
Yes |
Yes |
Yes |
Yes |
Prediction of a quantitative feature |
2.39 / 3.98 / 18.39 |
Classification |
Yes |
No |
Yes |
Yes |
Prediction of a binary quantitative feature |
« Yes » / « No » |
Multi Classification |
Yes |
No |
Yes |
Yes |
Prediction of a qualitative feature whose cardinality is > 2 |
« Victory » / « Defeat » / « Tie game » |
Object Detection |
No |
No |
Yes |
No |
Detection from 1 to n objects per image + location |
Is there a car in this image ? |
Text Similarity |
Yes |
No |
No |
No |
Estimate the similarity degree between two text |
List your experiments¶
All your experiments are related to a project so in order to Create a new experiment, you need first to create a project .
On the homepage of your project, you can see a summary of your project ressources and access to the experiments dashboards form the left sidebar
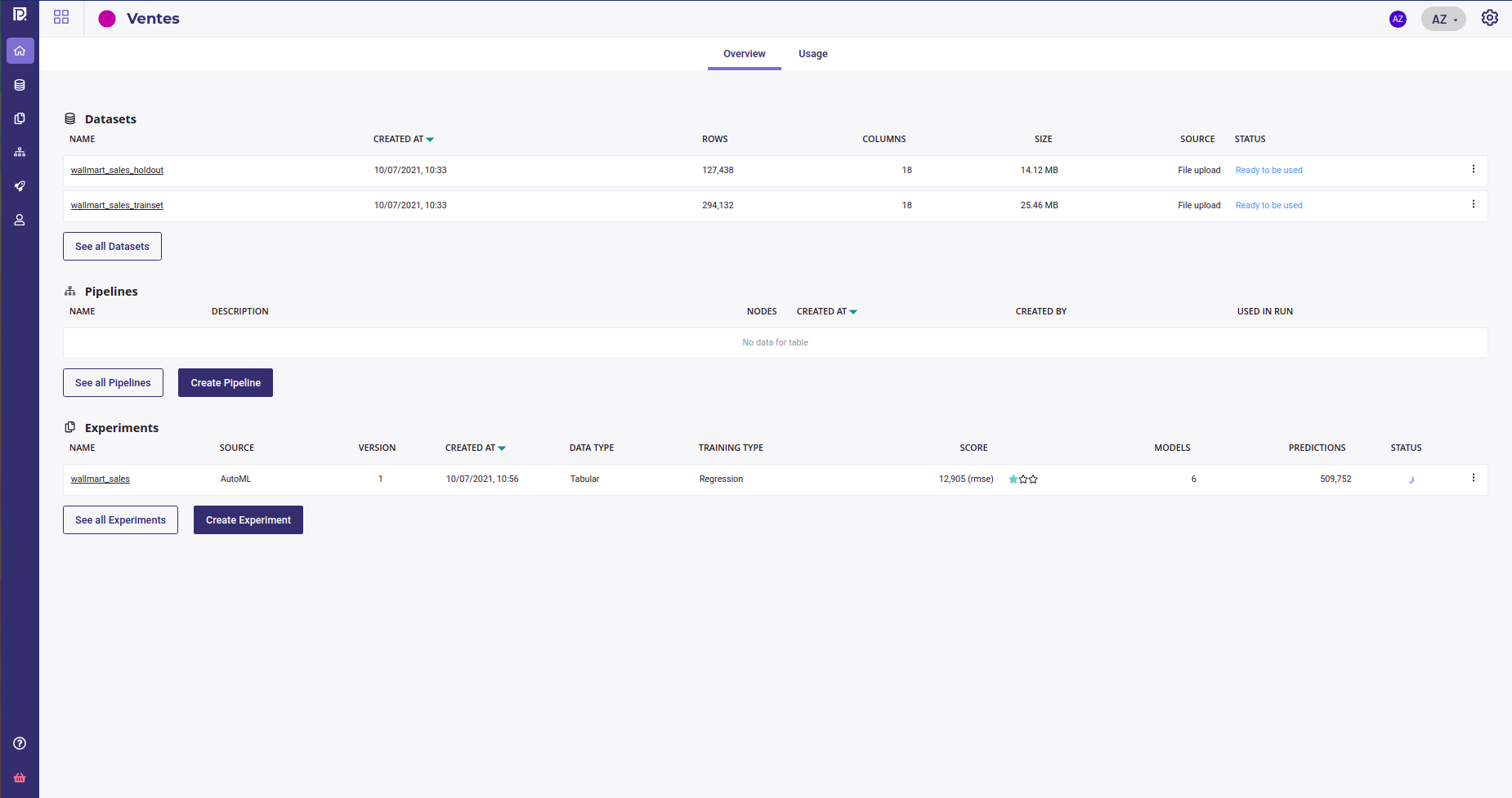
which allows you to navigate and filter all your project’s experiments from the experiments table
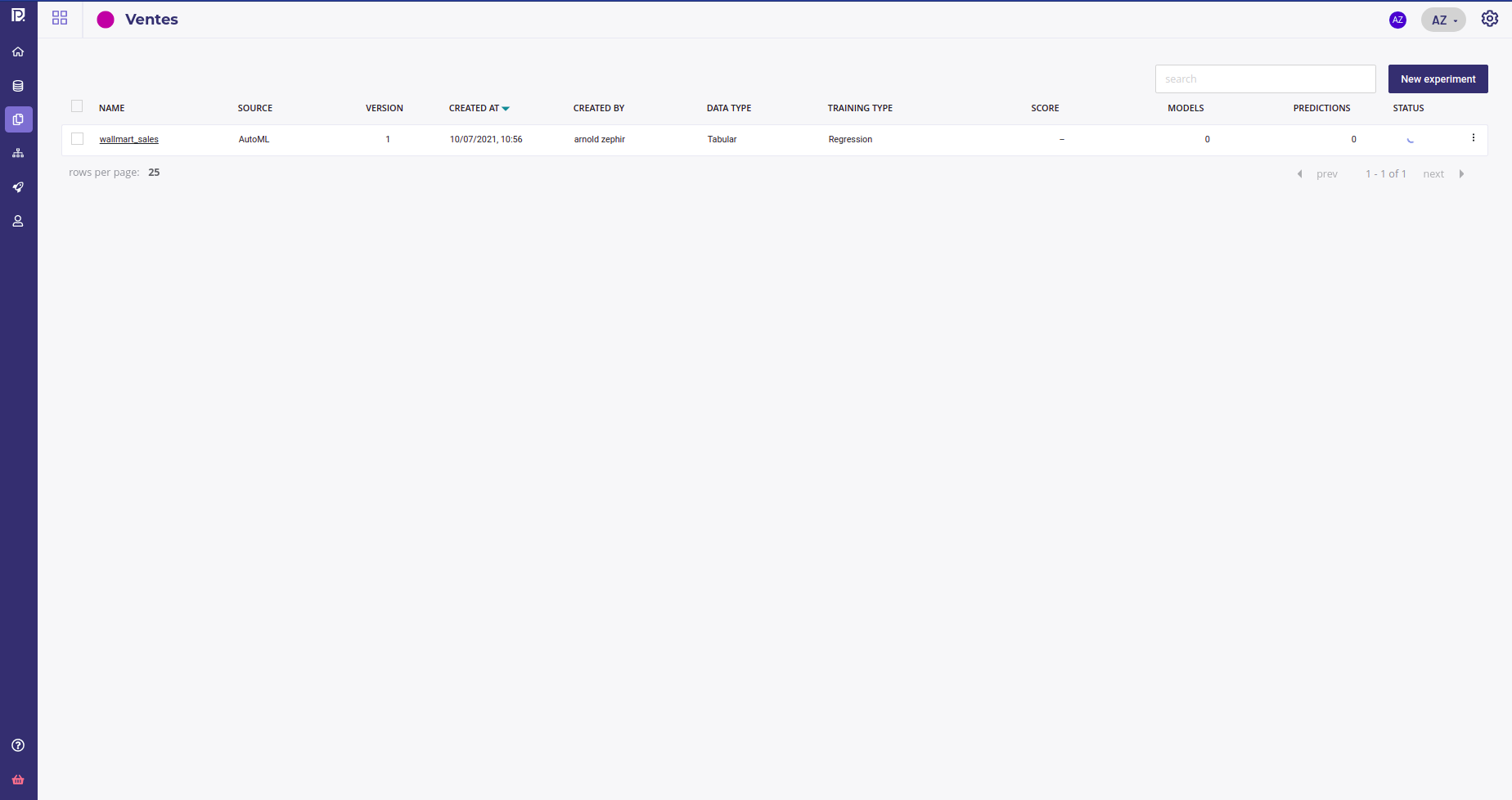
Each row gives you :
the name of your experiment, that links to the experiment dashboard
the source of the models of your experiment, AutoML or external models
the latest version of your experiment
the creation date and time of the experiment
its creator ( see Contributors )
the datatype ( Structured Data, Computer Vision Model or Time series )
the training type ( Regression, Classification, Multi-classification, Object Detection or Natural Language Processing )
score : the choosen metrics of the last version, the type of metrics and a 3-stars evaluation
the number of models built into the last version of your experiment
the numbers of predictions done over the last version
and the status ( running, paused, failed or done )
Create a new experiment¶
Note
Experiment is a way to group several modelisation under a common target in order to compare them and track progress. An experiment may have one or more Versionning your experiments and you can change any parameter you want from version to version ( Trainset, features used, metrics,…). The only constant between experiment are :
the target used. Once you had selected your target, you cannot change it and muste create a new experiment if you want to try a new one
the Engine used, AutoML or External Model
Once you had created a project, you can create a new experiment from the project Dashboard or the list of experiments, by clicking on the “Create experiment” in the bottom left corner of project dashboard or on the “New experiment” in the experiments list.
AutoML Engine and ONNX import¶
The first things asked will be to choose between AutoML or external model and to give a name to your experiment. AutoML use Prevision.io engine to choose and built the best model without human intervention from the shape and type of your data. External model is the mode for importing models saved as onnx file. Both allow to evaluate, deploy and monitor your model.
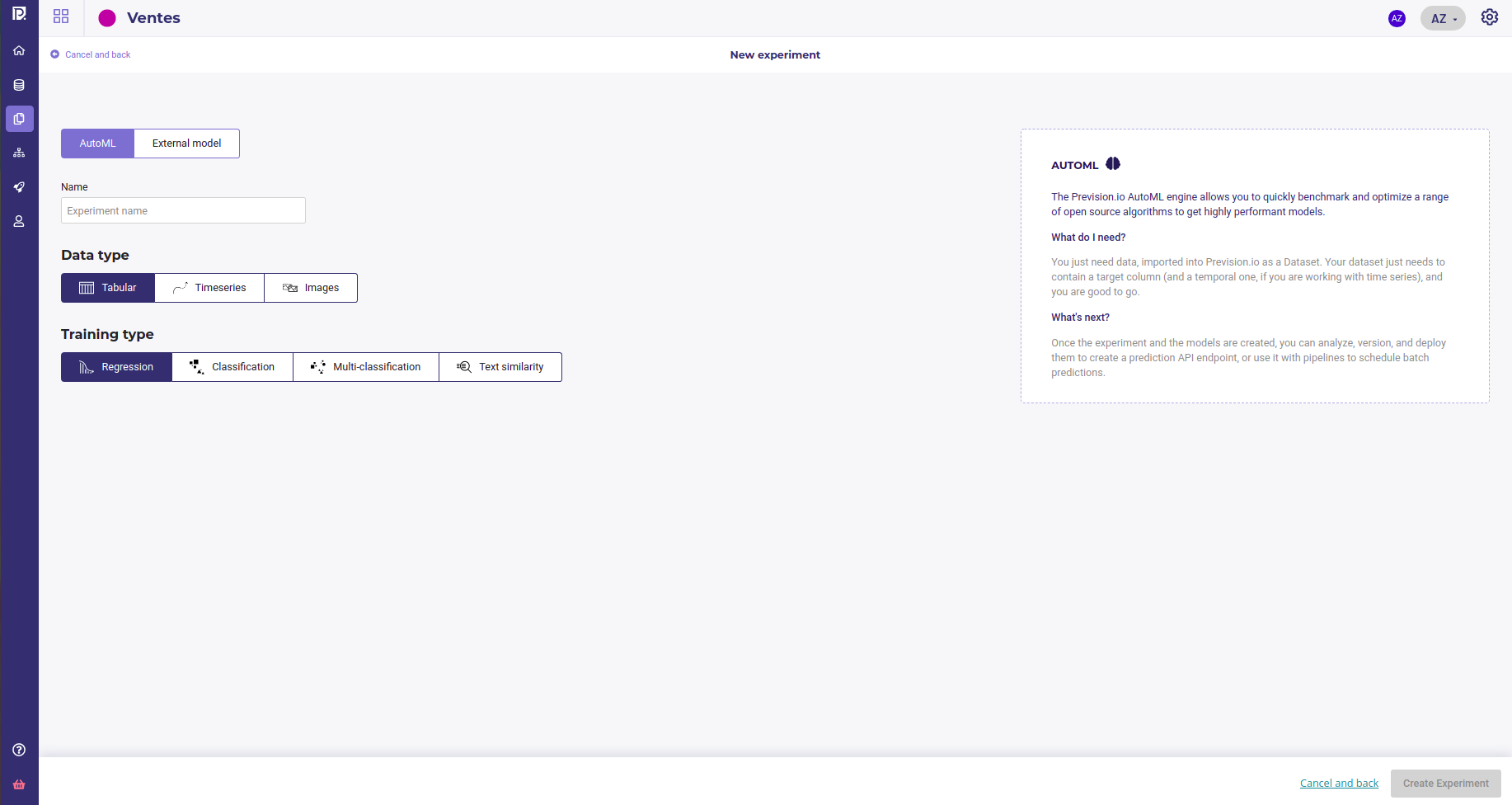
You can then select your Data type and problem type remembering this restrictions :
Training type / Data type |
Tabular |
Timeseries |
Images |
Available for External Model ? |
Definition |
Exemple |
|---|---|---|---|---|---|---|
Regression |
Yes |
Yes |
Yes |
Yes |
Prediction of a quantitative feature |
2.39 / 3.98 / 18.39 |
Classification |
Yes |
No |
Yes |
Yes |
Prediction of a binary quantitative feature |
« Yes » / « No » |
Multi Classification |
Yes |
No |
Yes |
Yes |
Prediction of a qualitative feature whose cardinality is > 2 |
« Victory » / « Defeat » / « Tie game » |
Object Detection |
No |
No |
Yes |
No |
Detection from 1 to n objects per image + location |
Is there a car in this image ? |
Text Similarity |
Yes |
No |
No |
No |
Estimate the similarity degree between two text |
You can learn more about AutoML and external models on their dedicated section :
Data type¶
Data type is, obviously, the type of your data :
Hint
Most of nlp problems should be considered as tabular data whom one or more columns are text. If any columns is detected as a textual one, Prevision AutoML engine will apply a set of standard NLP embedding technics ( tf/idf, Transformers, seq to seq,…). The only limitation is that you cannot yet build generative model ( so no automatic summarisation ) but if you want to classifiate or rate docs or email, tabular data is the way to go.
As far as that goes, image are used in a tabular way too, except for the object detector. When choosing data type image, you will used a dataset whom on feature is a path to some image uploaded in your image folder. You can run Classification or Regression on Image !
tabular : data from csv, sql database, hive database, … suitable for classification and regression
timeseries : when target depends on time, use a timeserie. Note that you should have data with constant timestep as much as possible and only regression are possible with timeseries
images : if you want to build an image-based model. Note that you can mix images and standard features in the same experiment. Image has a special probleme type ( Object Detection )
Training type¶
Training type is the kind of problem you want to solve :
Regression : when you need to predict a continous value. Suitable for sales forecasting, price estimation, workforce management, … can be used for image and text.
classification : when target has only 2 modalities, choose classification. For example fraud detection, churn prediction, Risk management,…
multi-classification : if your target has more than one modality. Standard example are product cross sale, Transport Mode detection, Evaluation prediction, email classification, sentiment analysis …
Text similarity : this training type is dedicated to retreive doc from query. The input is tabular data with at least one column of docs ( text ) and the model will be trained to attribute later query to one of this original doc. It’s useful for searching item from their description or build chatbot to anwser to user questions
Object-detection : Object detection train a model to detect some object on image, attribute a class and return a bounding box. For example you can detect pools on satellite image or type of french cheese on a photo
And get a more details about each Problem type :
Whatever your choice, when you create a new experiment, you will be prompt to create the first version of it.
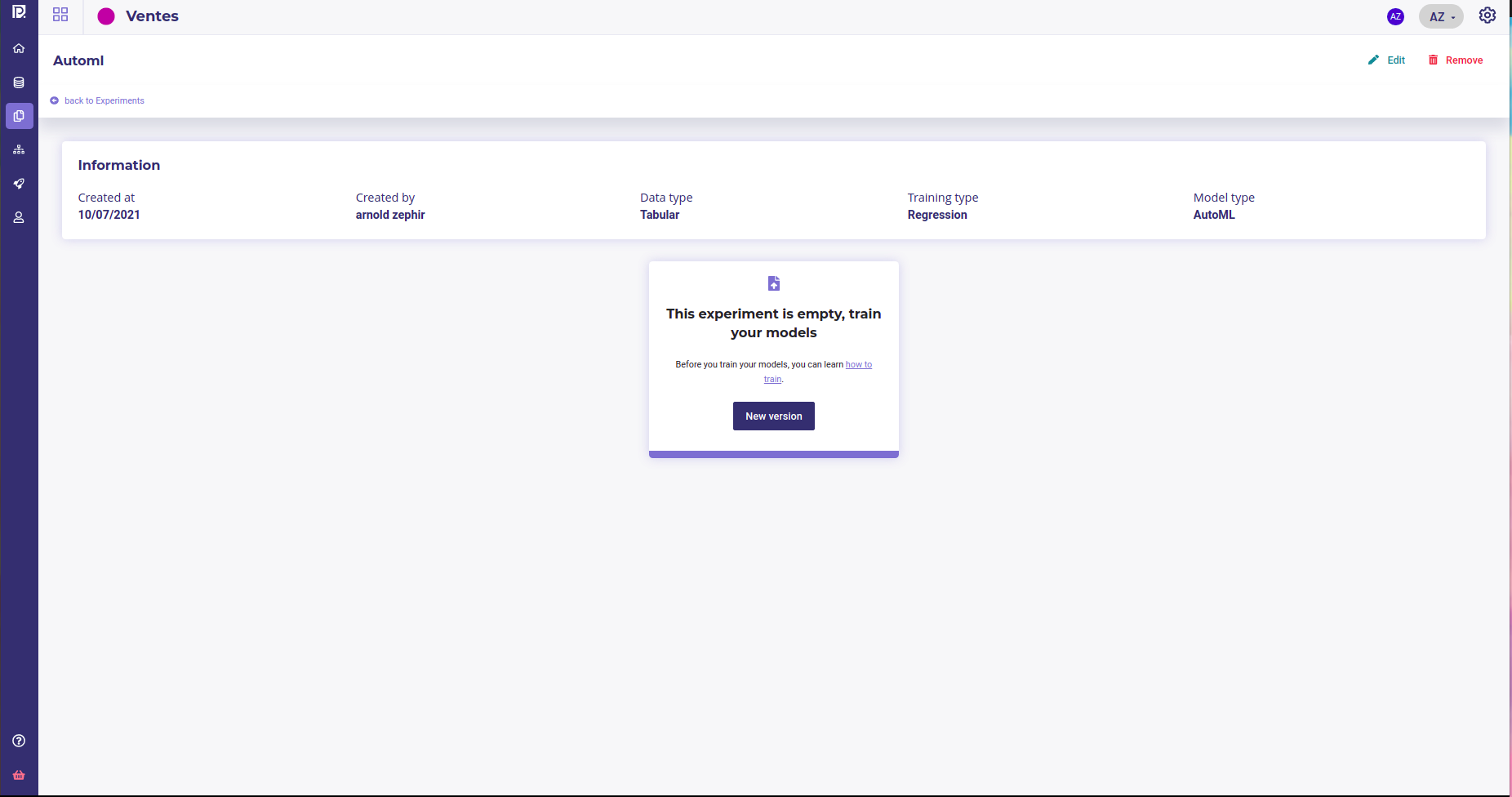
When clicking on new version, you will enter the configuration screen, that depends on the engine you choose
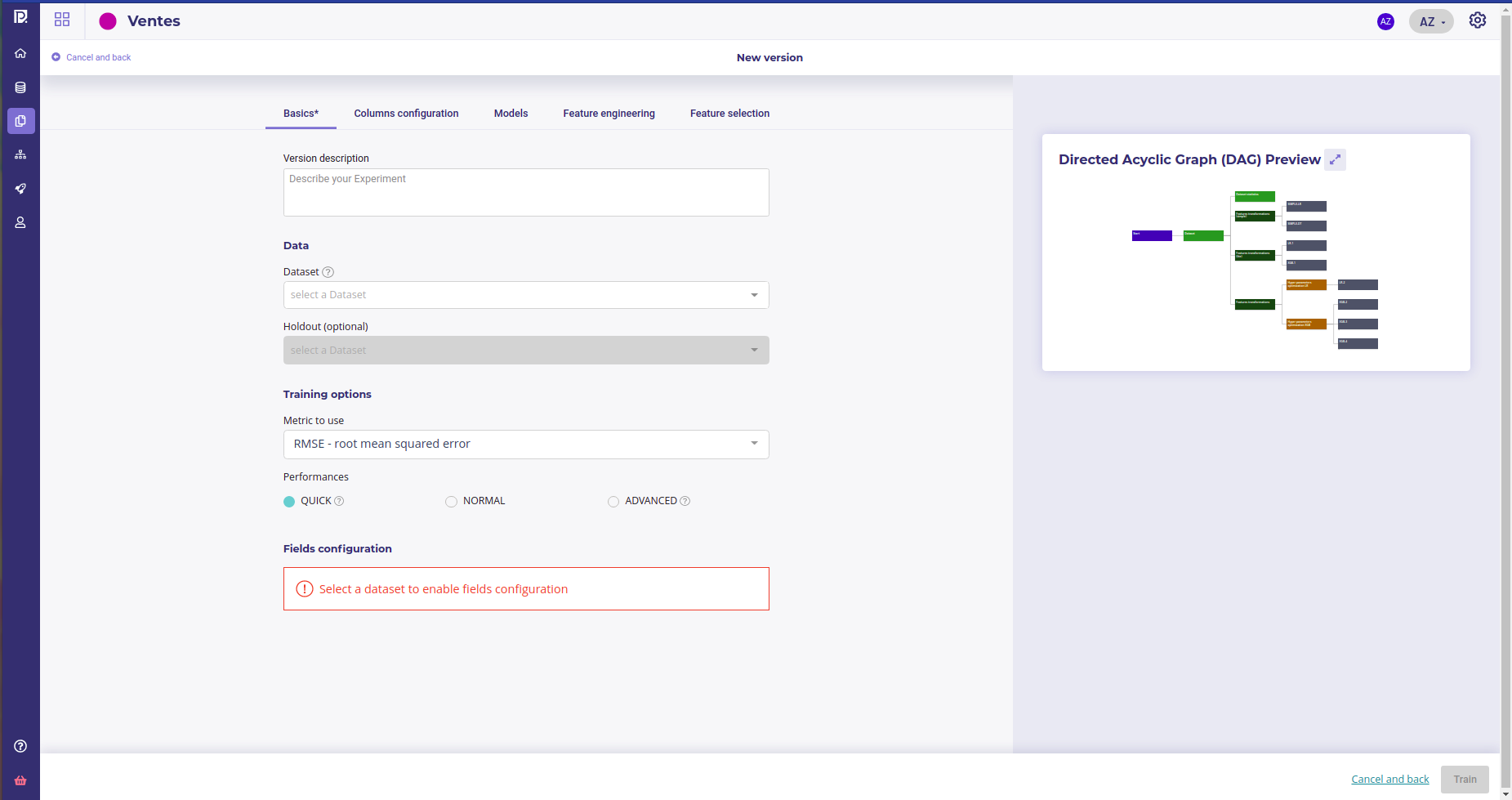
automl configuration screen, with the graph of tasks that is gonna be executed¶
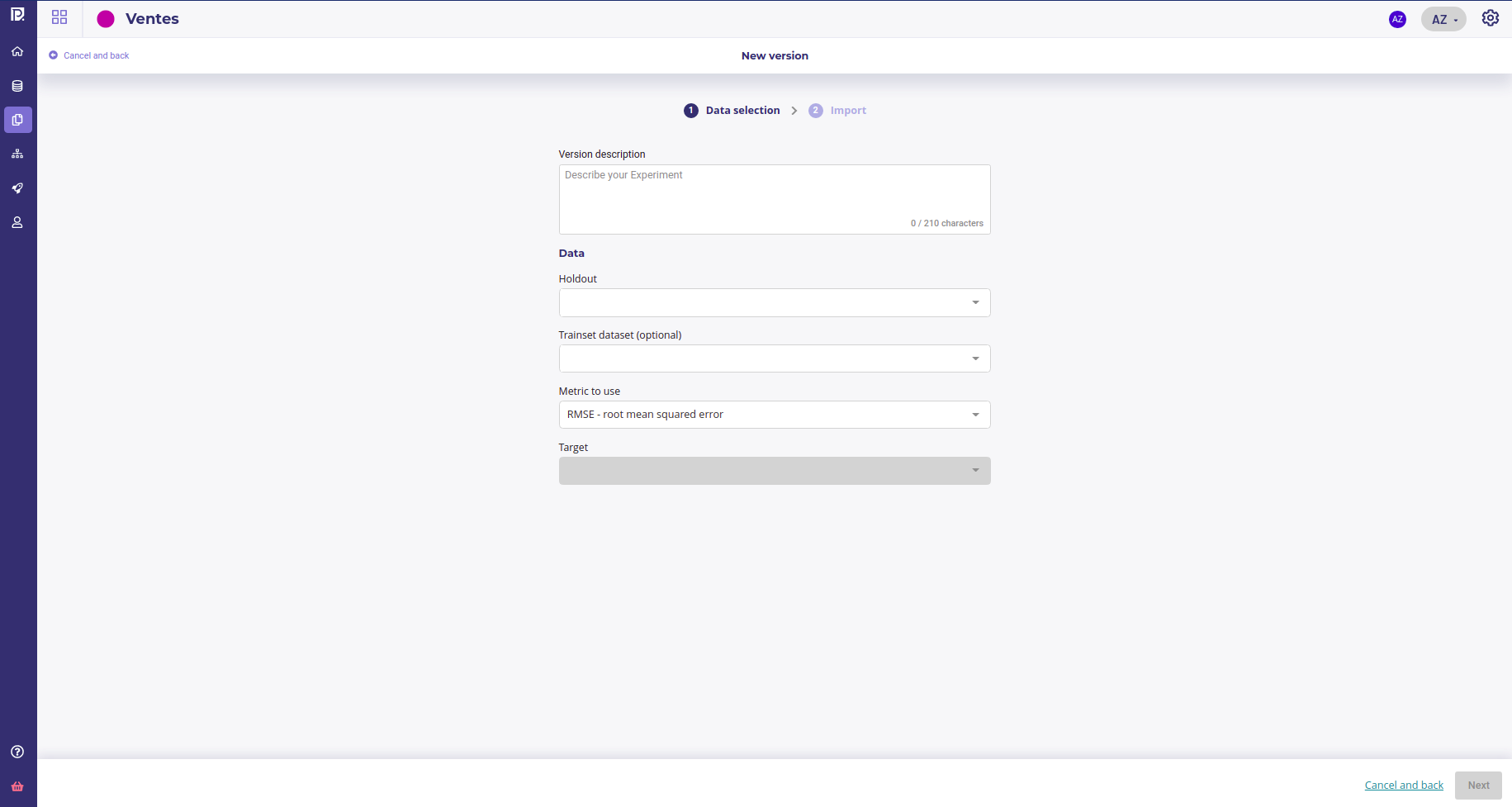
The external model configuration screen¶
For the first version only, you need to fill the target field to set the common target for all versions of your experiment.
Once every mandatory parameters are fill ( see each training type doc for an explanation of parameters ), you can click on “train” to launch a train and start modelisation.
Import External models into your experiment¶
If you already have models built form others frameworks, so called external models you can import them to benefit from Prevision.io evaluation and monitoring tools.
See the dedicated page
Inspect your experiment and evaluate your models¶
Once an experiment has at least one version, you can get some details about it on its corresponding dashboard by clicking on its name in the list of experiments.
The default dashboard is those of the last version of your experiment. If you have many version of your experiment, you can change it with the dropdown menu on the top left corner.
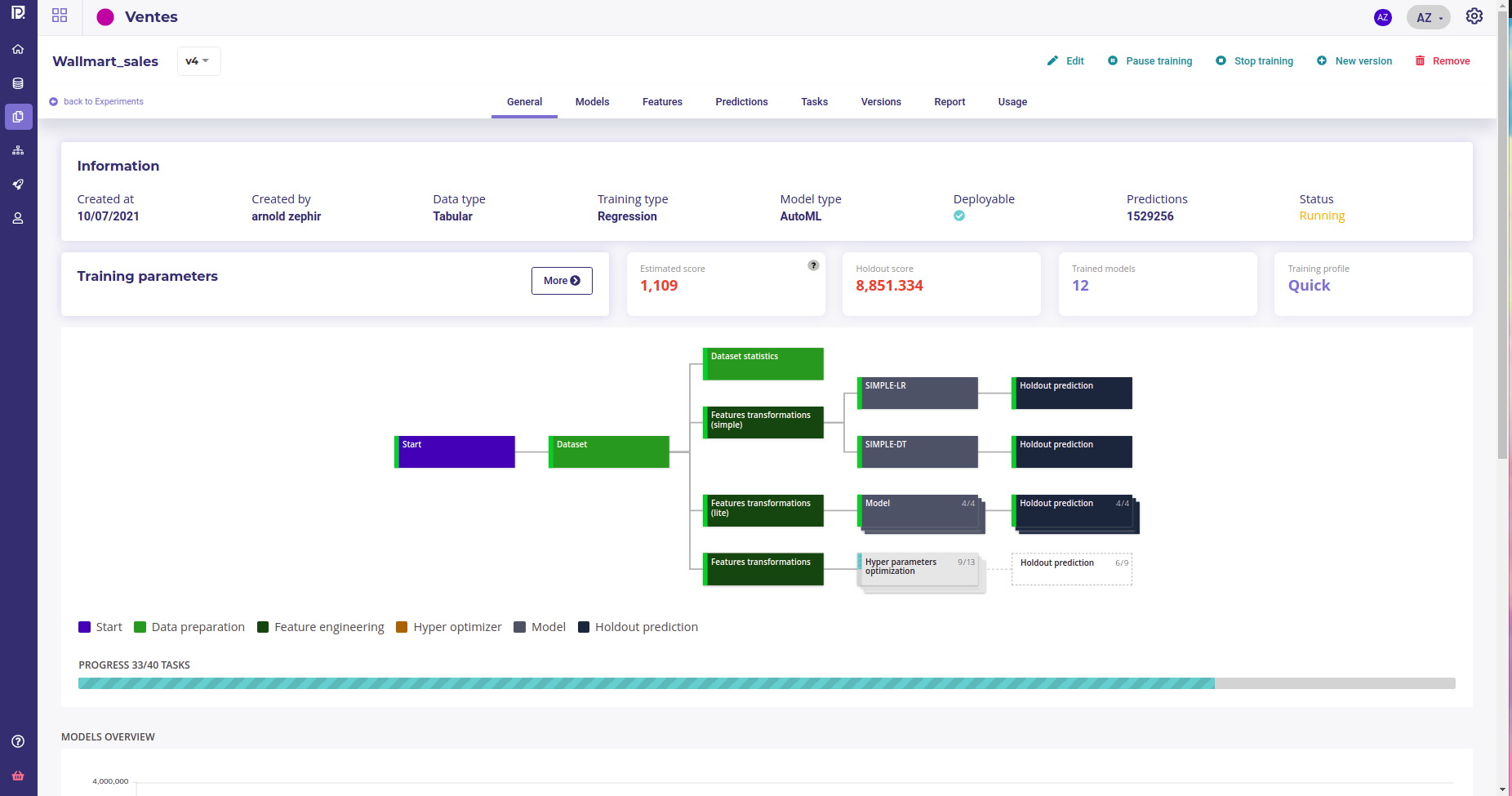
The front page of experiment dashboard shows you :
General : general information and comparison of your models in terms of performances
Models : list view of the created models and information about the trained models
Features : information about the way the features are used for the training and the configuration of the feature engineering
Prediction : create bulk predict using CSV files and view all bulk predictions done for this usecase
Task : Graph and listing of all operations done during training
Versions : list of all version of the selected usecase
Report : generate PDF reports explaining the models/usecases
The information header gives you the important information regarding your usecase. You can navigate through the versions using the dropdown list on the left side of this panel.
Action button : on the top-right corner of the page arethe actions buttons allowing you to :
edit the name and description of the experiment version
create a new version
delete the experiment
Under the information panel, cards displaying information regarding your usecase are displayed. Please note that the holdout score card will be displayed only if a holdout was selected during training configuration
Two graphs are displayed on the general page of a usecase showing : - The models ranked by score. By clicking on a model chart bar, you can access to the selected model details - Models score vs. estimated prediction time
Please note that for object detection, the general screen is quite different from the other use cases types. On the image detection general menu you will find a sample of images used during the train in orange, the predicted bounding boxes using cross validation and in blue, the true bounding boxes.
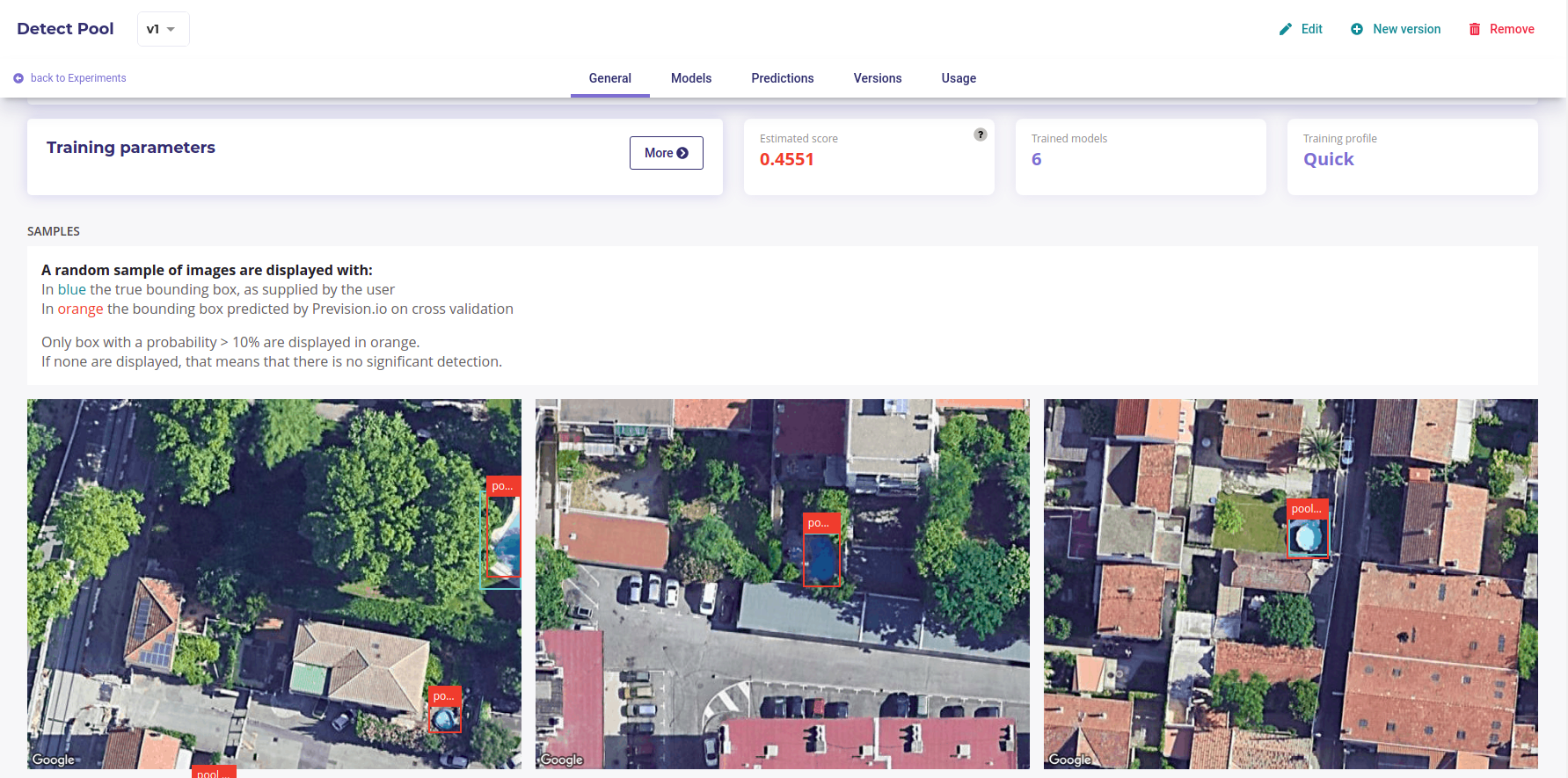
Object detector dashboard¶
Tasks¶
In this menu you will find an overview of all tasks made by the platform during the usecase training and their status. The aim of this screen is to help you to better understand the operations made during the training and, if errors occurred, at which level it happened. When a task failed, you can access logs by clicking on the logs button taht appears.
Two views are available :
Liste view : list all single operations done
DAG view : graphical view of single operations and their relation
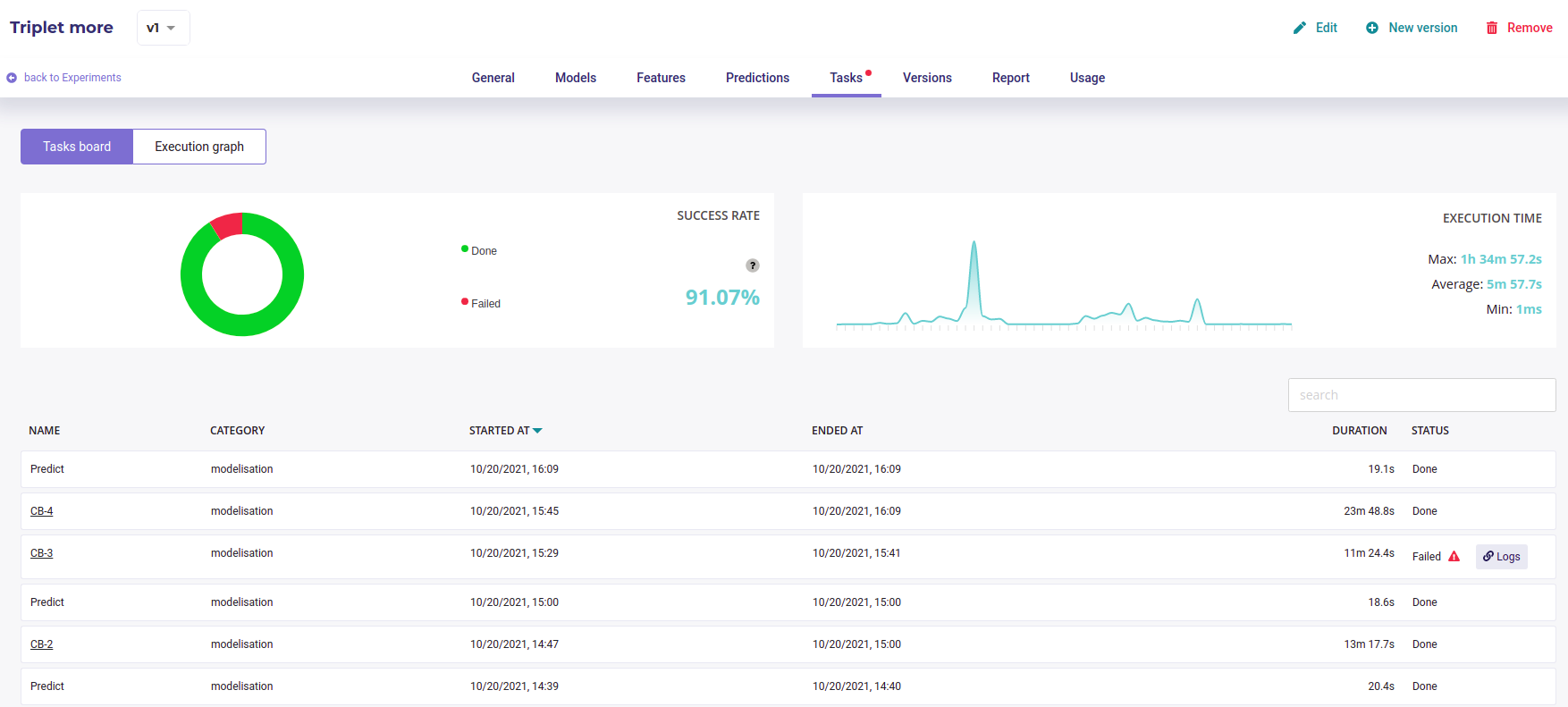
All the tasks executed¶
You can switch between these views by clicking on the execution graph / tasks board switch.
Reports¶
In this menu, you can generate PDF reports regarding models from the usecase. To do that, once on the dedicated model menu, you will have to choose from the drop down the models you want to appear in the generated report and the feature importance count. You also can select explanations by check/uncheck the show explanation checkbox. Then, by clicking on the generate button, you will get an overview of the report. By clicking on the “print” button on the top of the overview, you will download the PDF report.