Pipelines¶
In Prevision.io platform you can automate several actions using the pipeline editor. We will see in this chapter the possibilities of the pipelines and its components and how the editor works. In order to execute a pipeline, several requirements need to be fulfilled :
first, you have to create your own template using the pipeline editor. This template includes generic components with no configuration required in this step. This allows you to create a generic template and apply it several times on different experiments by configuring the component.
then, you will be able to configure the pipeline run by choosing an already created pipeline template and by configuring the nodes to your experiment. You also can choose to run the pipeline manually or automatically by using the scheduler.
Optionally, you can create and load into the platform your own components and use them into pipelines.
Before going into detail about the creation of pipelines itself, let’s have a look at the pipeline components existing in the platform and their purpose. This overview will help you to better understand the possibilities of Prevision.io pipelines
Pipeline components¶
Pipeline components can be considered as steps, or nodes, of the pipeline. Several categories of components are available in order to easily find them when building a pipeline template.
Some Components are provided on the shelf when you subscribe a Prevision.io plan.
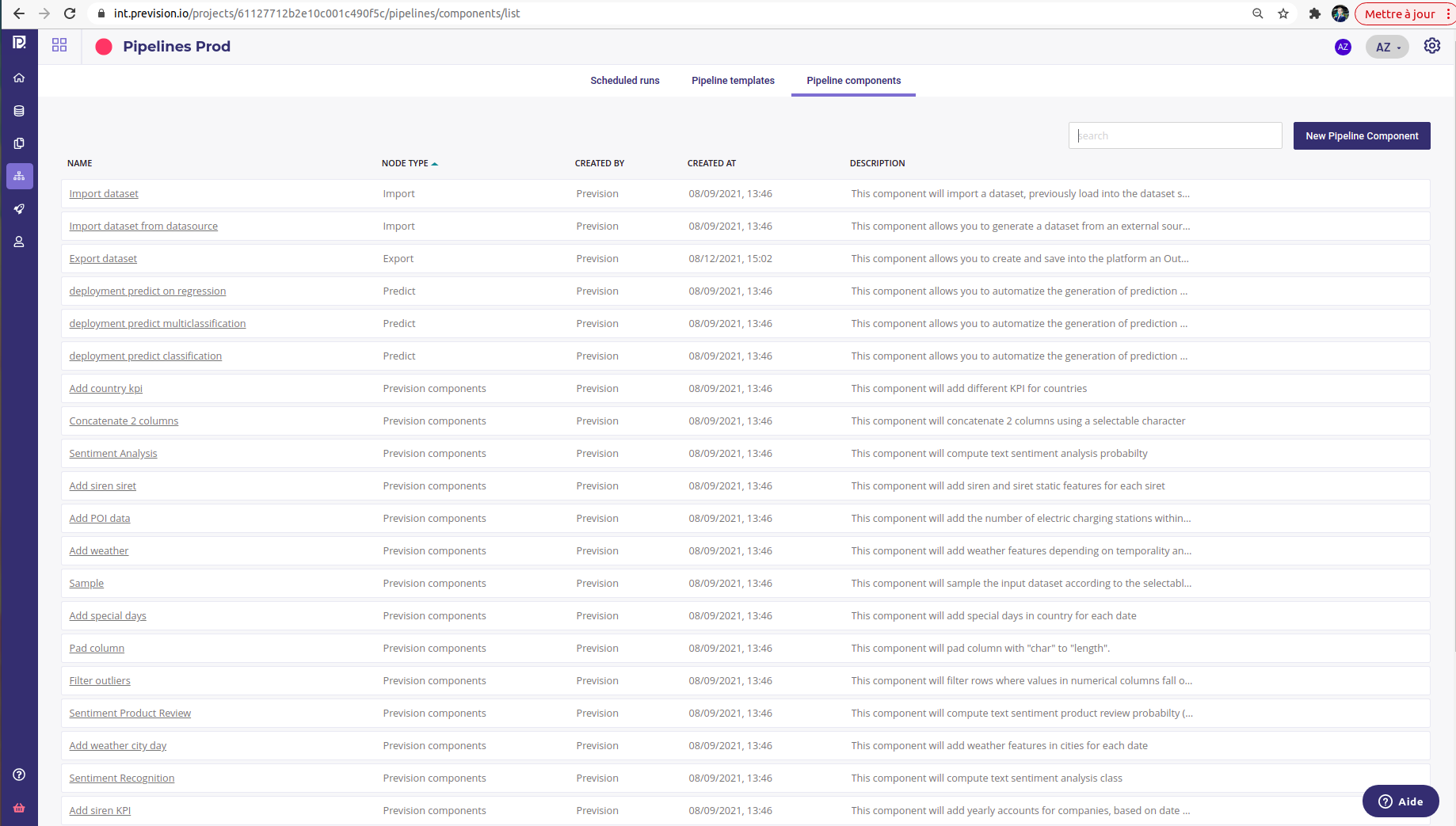
Import : All component relative to the import of data
Export : All component relative to the export of data
Prevision component : Various component developed by Prevision.io datascientists for their various projects
Custom component : Components developed by you or your team
Predict : All components relative to the automatisation of the predictions
Retrain : All components relative to the automatisation of model training
Each component has a description helping you to choose the ones suitable for your needs. You can access all components by clicking on the pipelines menu on the side project’s menu and, navigate to the pipeline components menu.
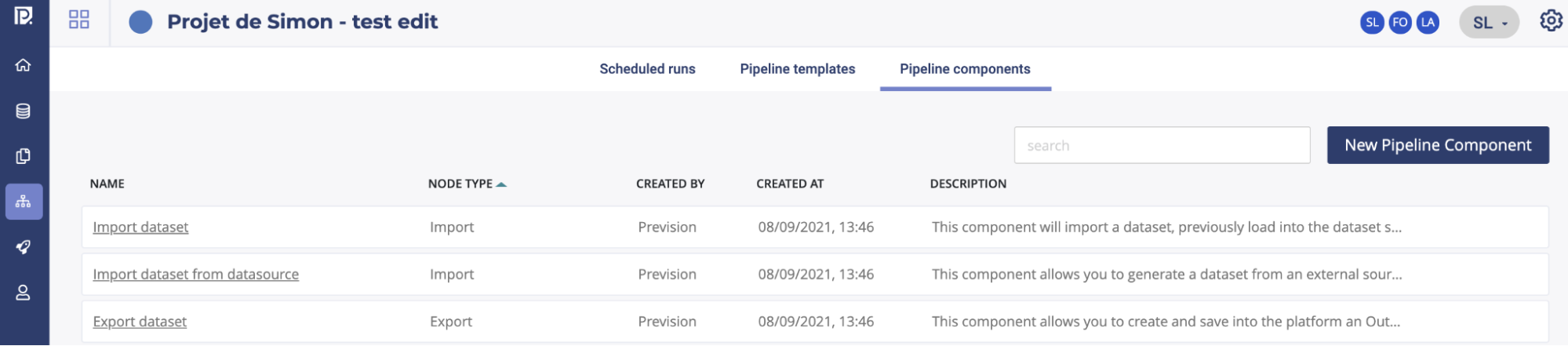
Building you own component¶
You can build and use your own component for custom dataset transform.
A boilerplate with more guide is available on the Prevision.io public repo
To use your own component you need a gitlab or a github account ( and it needs to be setup in your account page )
Once done, your component may be use in any Pipeline Template.
Pipeline templates¶
Pipeline Template are a tool for describing operations to schedule. In a pipeline template, you do not input any parameters. Instead your build a pipeline by linking nodes togethers and setting some placeholder.
Your pipeline template will then be used in the schedule step, where you, or someone else, is going to fill the placeholder with their inputs.
For example, you can define a template that “add an integer to the age column”. The value of this integer will fill in when a scheduler use your template.
A template may be used in different scheduled run with different parameters each time.
In order to create a new pipeline template, you have to navigate through the pipeline template menu.
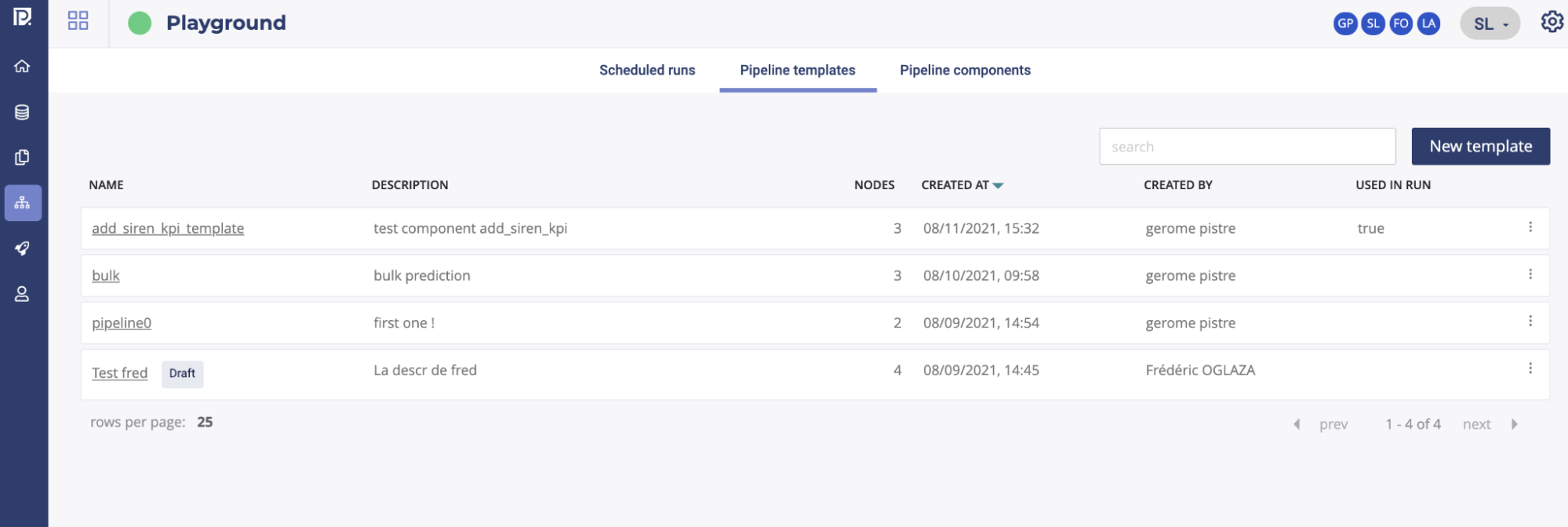
You will then access the pipeline template liste of the project. By clicking on the “new template” button, you will access to the pipeline template editor.
The first step is to set up the name of your pipeline template and, optionally, a description.
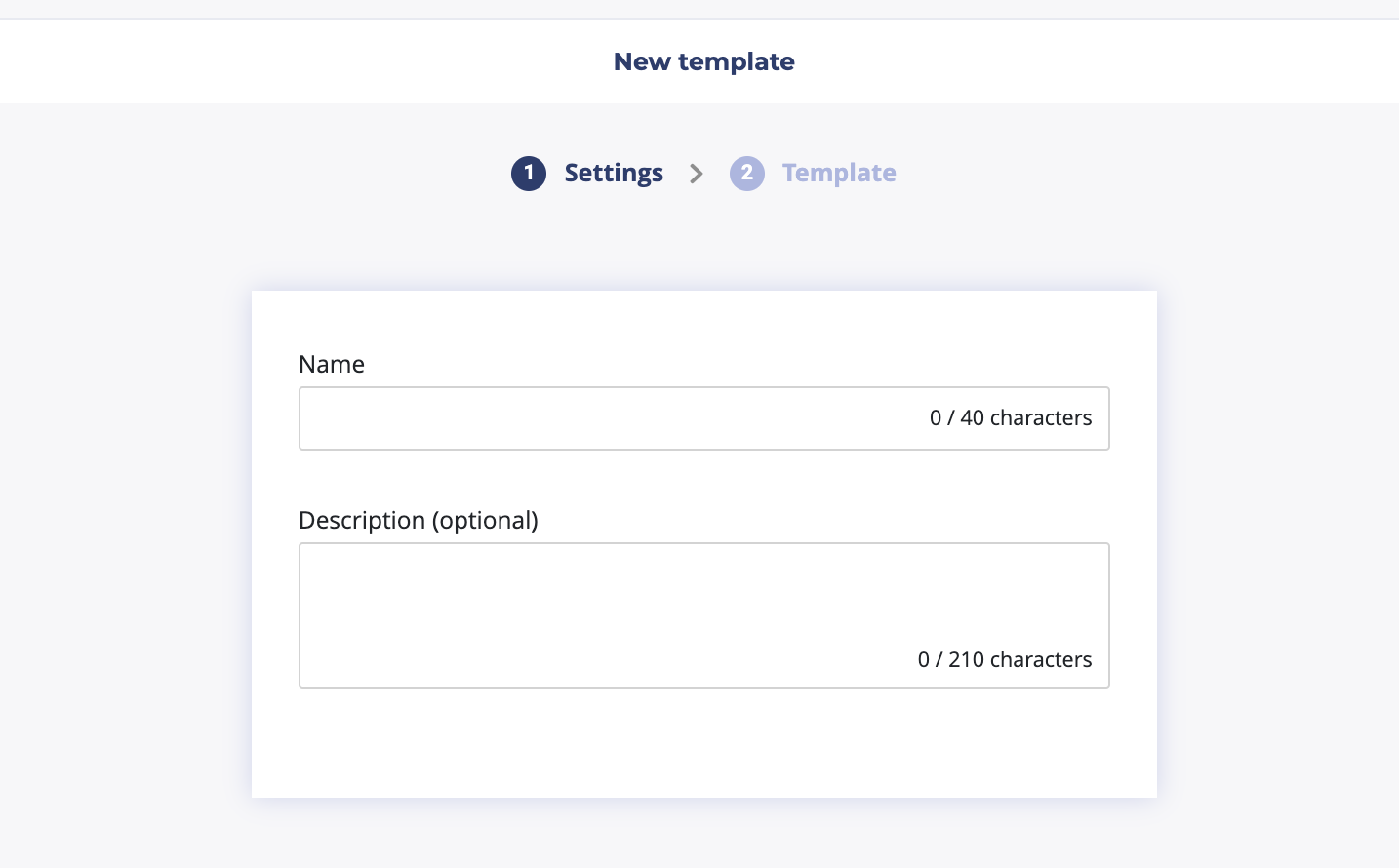
Once ( and only once ) the required information is fullfilled, you will be able to reach the next step by clicking on the next button bottom right.
Then, the pipeline graphical editor will be visible and you will be able to start the creation of your pipeline template. In order to add your first node, you have to click on the “+” button in the center of the graphical area.
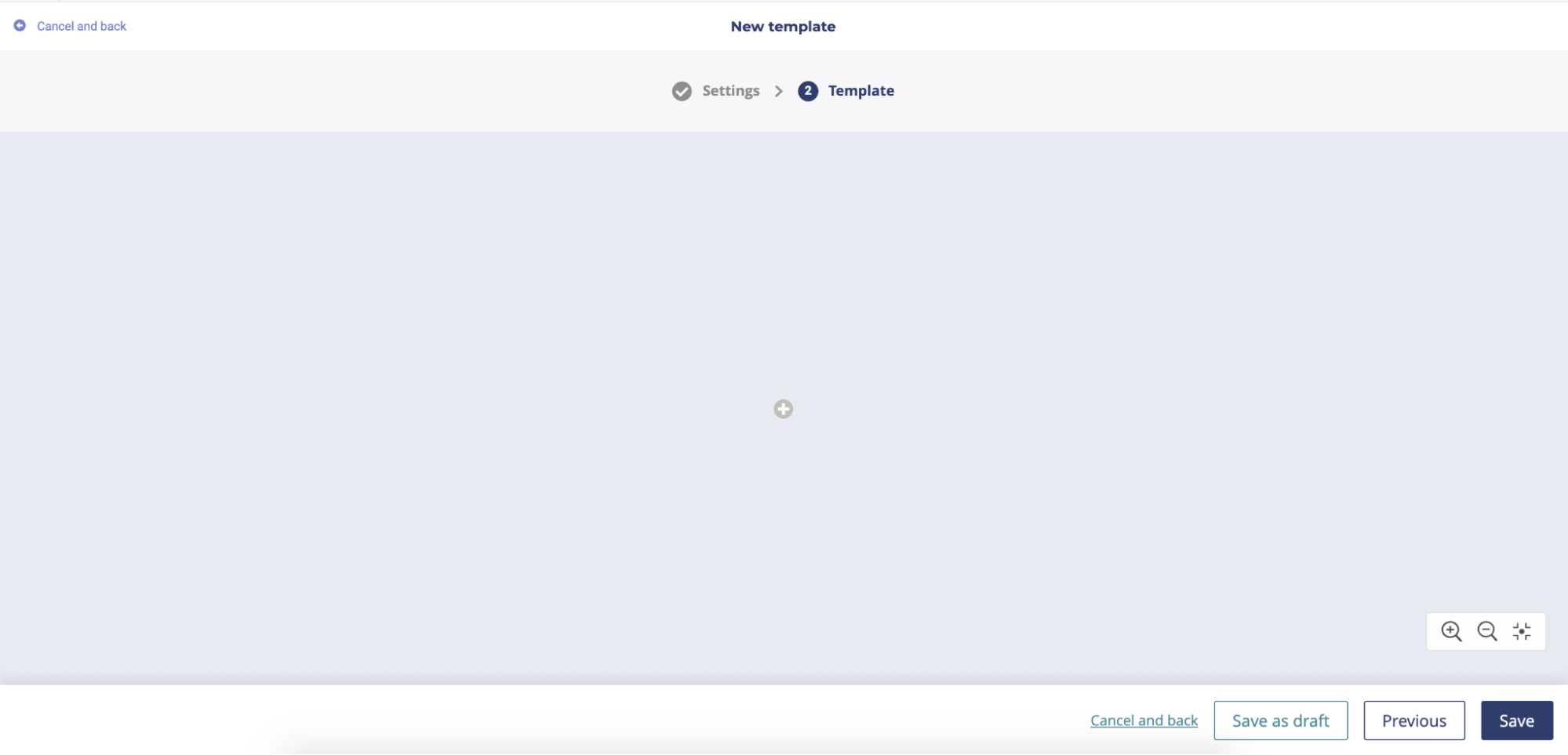
Then a popup window will appear allowing you to select the first node. In this popup, the components are classified in several categories. You can navigate through nodes categories by clicking on the top bar menu. In order to add a node, you simply have to click on it and save. Please note that the eligible nodes are colored unless ineligible ones that are in gray. This will help you through the creation of your pipeline in order to be sûre that the final result is conform to what the platform is expected.
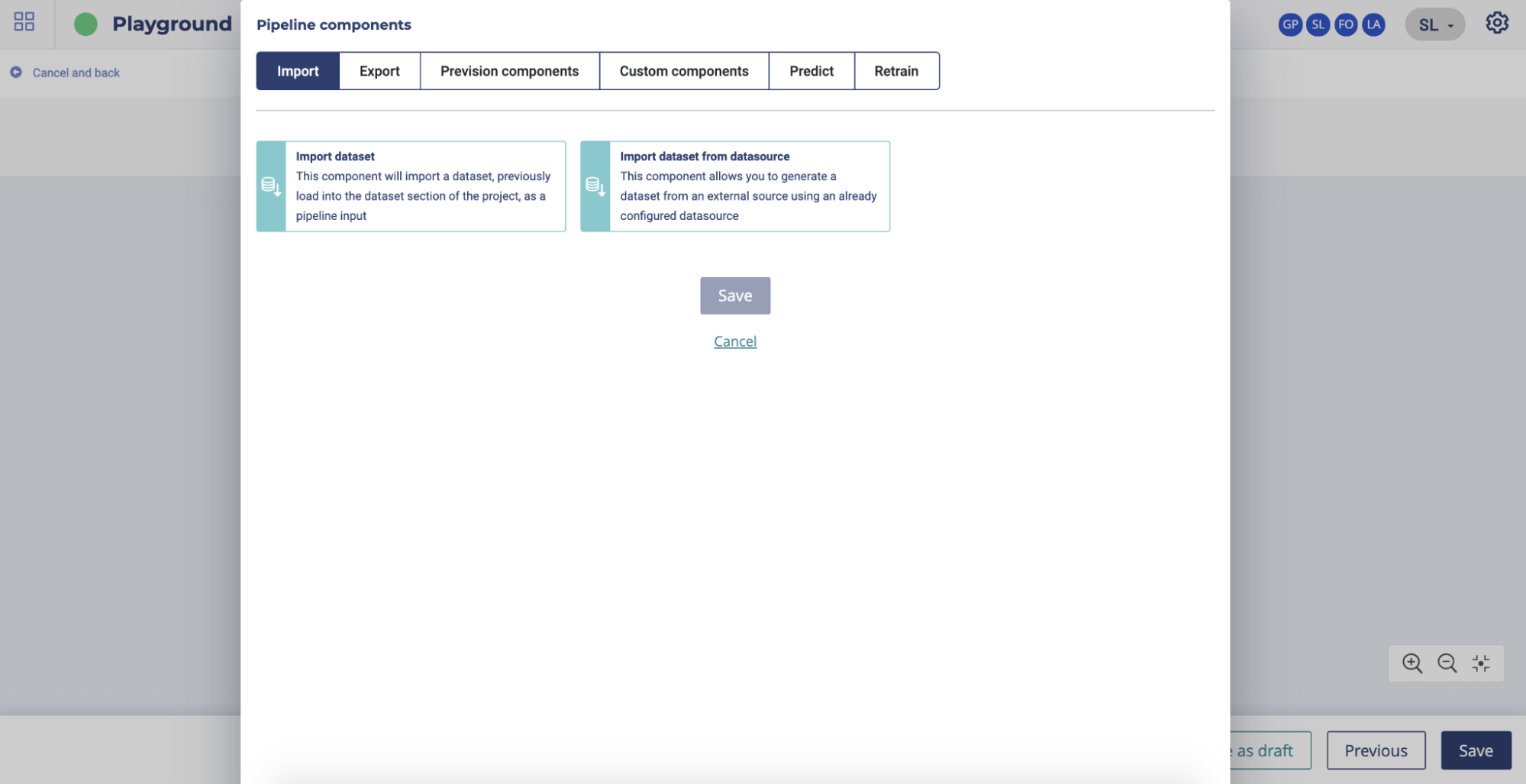
The selected node will be visible in the graphical view. Please note that you can save as draft your pipeline template in order to finish it later by clicking on the bottom right “save as draft” button.
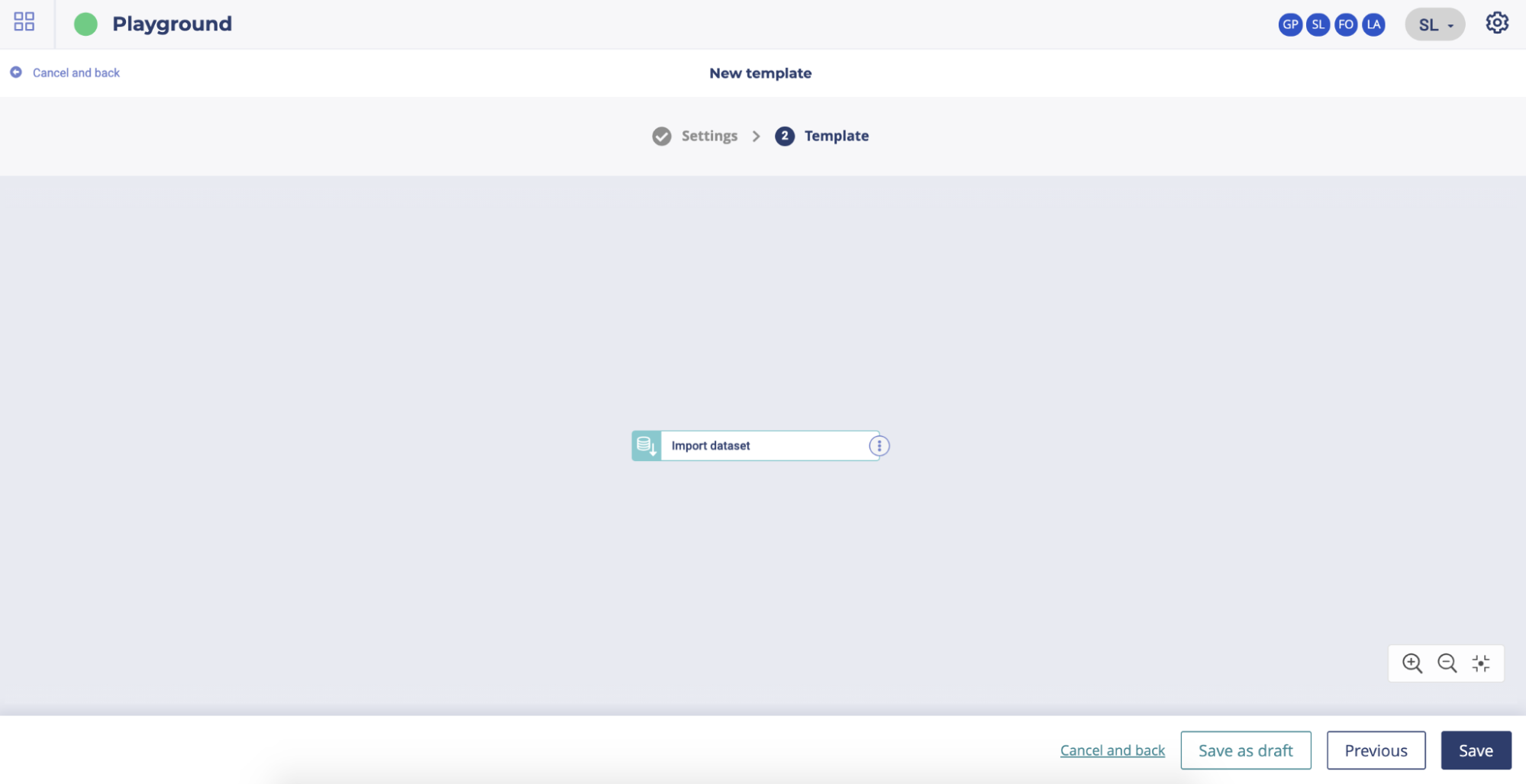
Several actions are possible on the newly added node. You can access to the possible actions by clicking on the more action button on the right side of the node.

Four actions are possible :
add a node after the selected one
switch this node for another
view settings of the node
delete the node
Please note that some special nodes can have limited actions.
Once your pipeline template is finished, you can save it by clicking on the bottom right “save” button. You will be then redirected to the pipeline template list.
Scheduled runs¶
A scheduled run is the combination of a pipeline template and a specific schedule. It allows to trigger some pipeline at regular interval.
Once you had defined a pipeline template, you can use schedule it for running :
Once
periodically forever
periodically for a defined period of time
When to used scheduled runs ?¶
In most of case, scheduled runs are used :
for delivering prediction on a periodic schedule. For example sending a list of churner to sales team each monday
for retraining a model, for example each first day of a quarter
for computing engineered features and pushing them to others teams on a regular basis
Create a new scheduled running¶
Scheduled run are available in the Pipeline section of a project, available under the “Scheduled runs” tab.
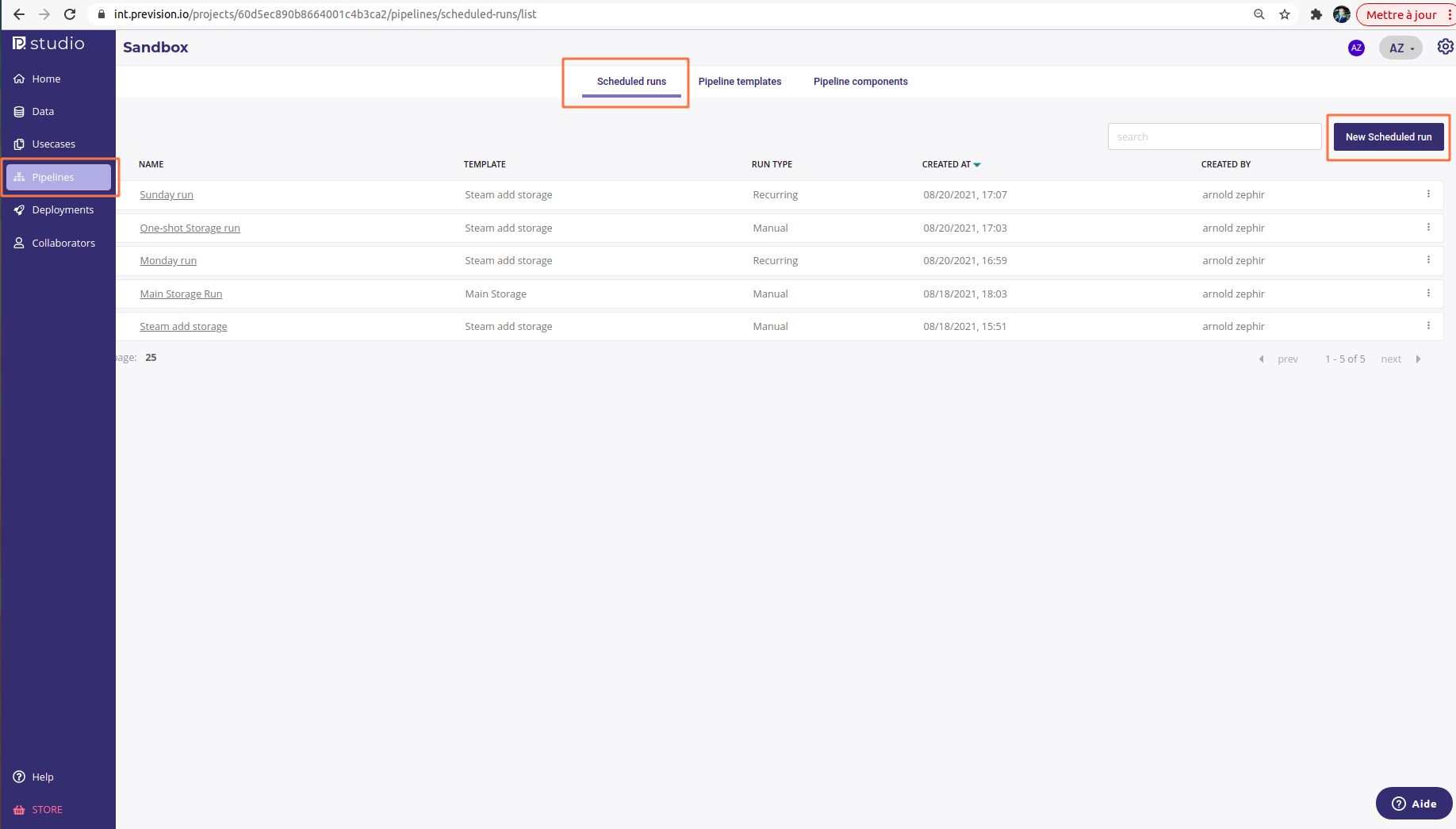
From the main page, you can view a list of all your scheduled runs and create a new one by clicking on “New Scheduled run” button
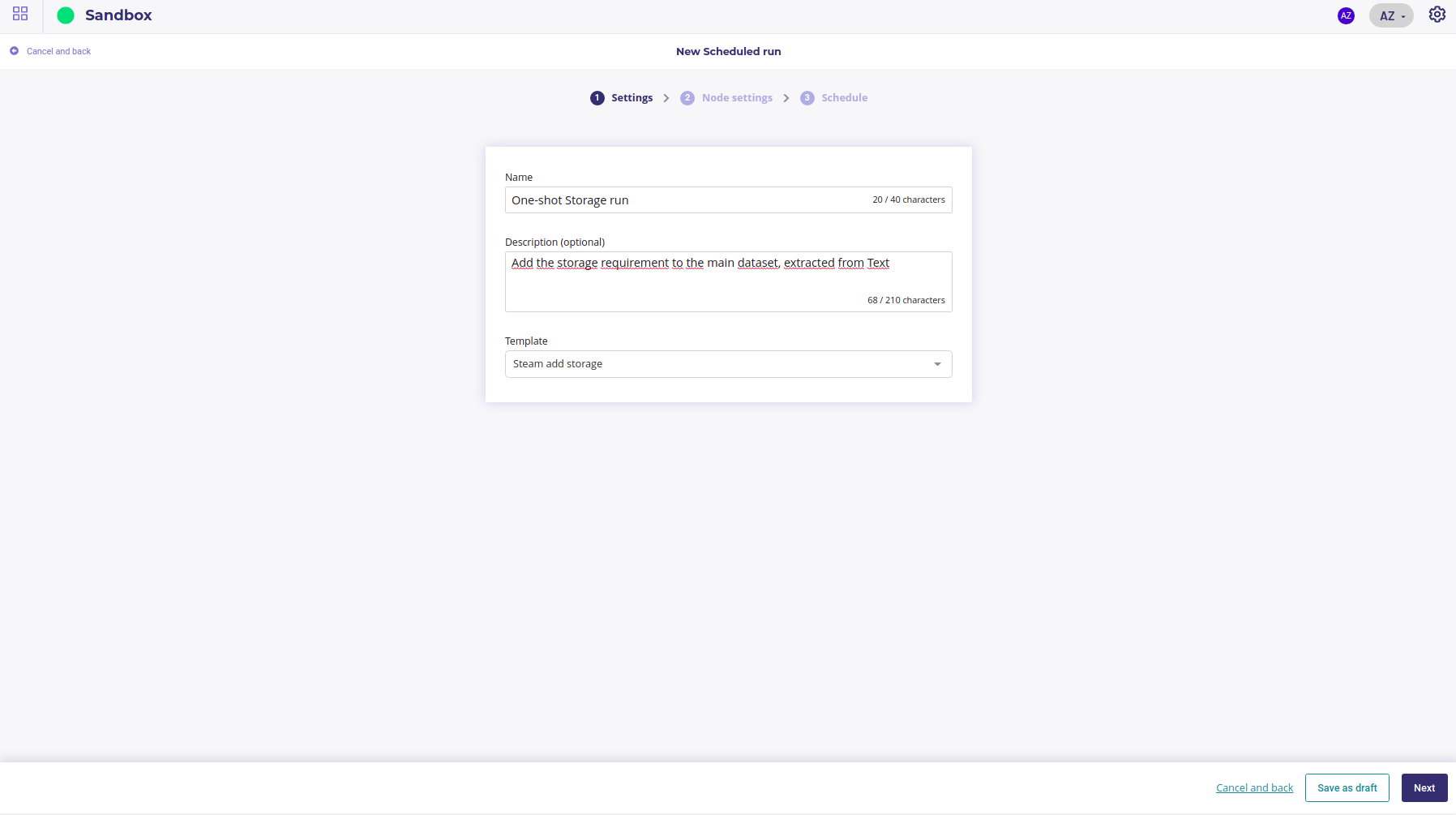
First step is to give a name and some description and select a pipeline template.
Select the template you want to fill in and click on “next” on the right lower corner.
Note
Pipeline templates were created in a previous step, with some input inside nodes to fill in. “Scheduled runs” is the place were you are to fill them up.
The next screen is were you fill all the parameter of your pipeline. For each node with one or more parameter to provide, a to configure yellow label is displayed on the node.
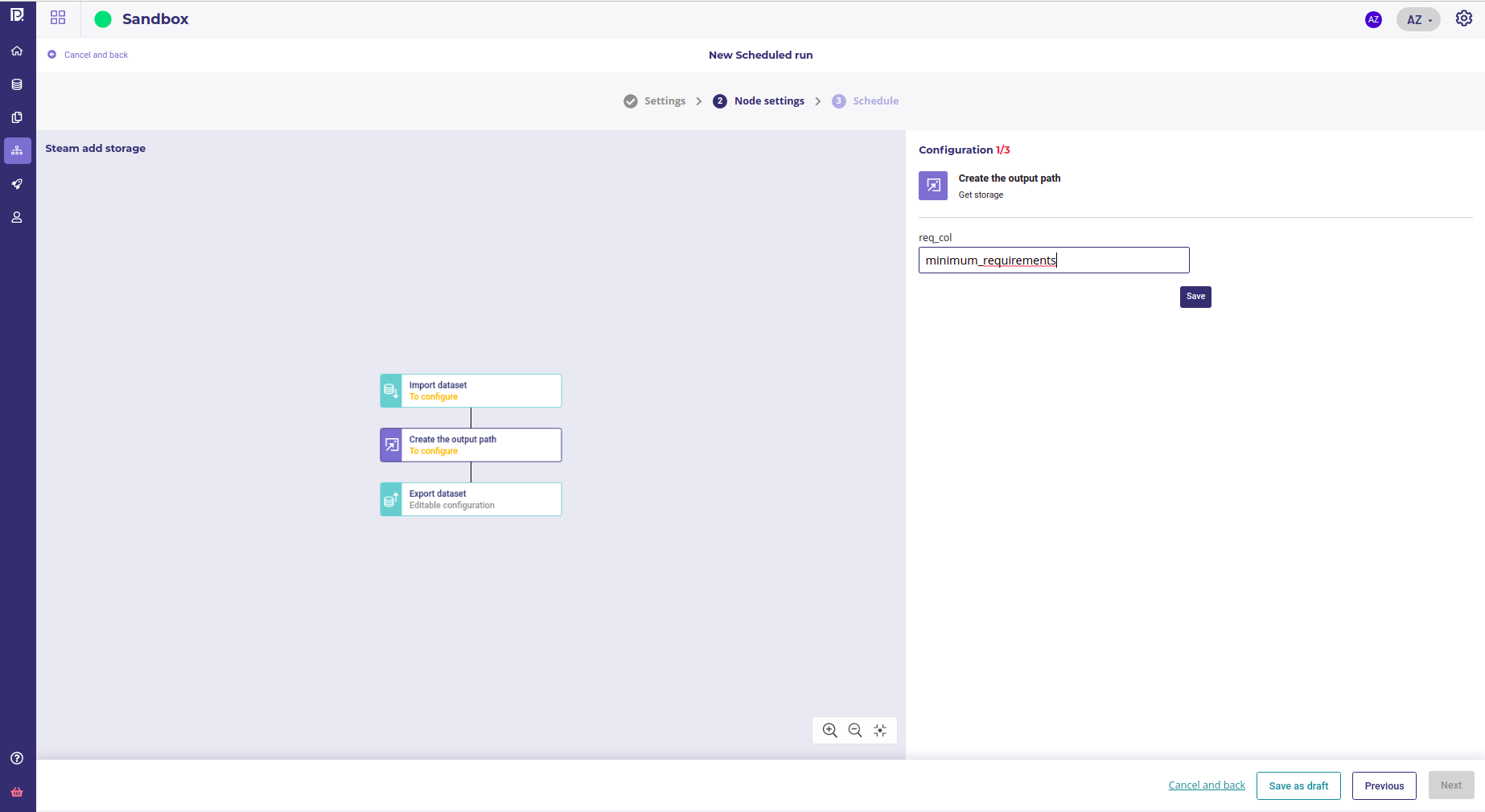
To enter a parameter, click on each node and fill the input. Click on save to save them ( parameters are not taking into account till you click on save ). To know more about a parameter, you may go to the “pipeline components” tab and click on the component to get input description.
Once you filled all the node parameters, there should be no more yellow label :

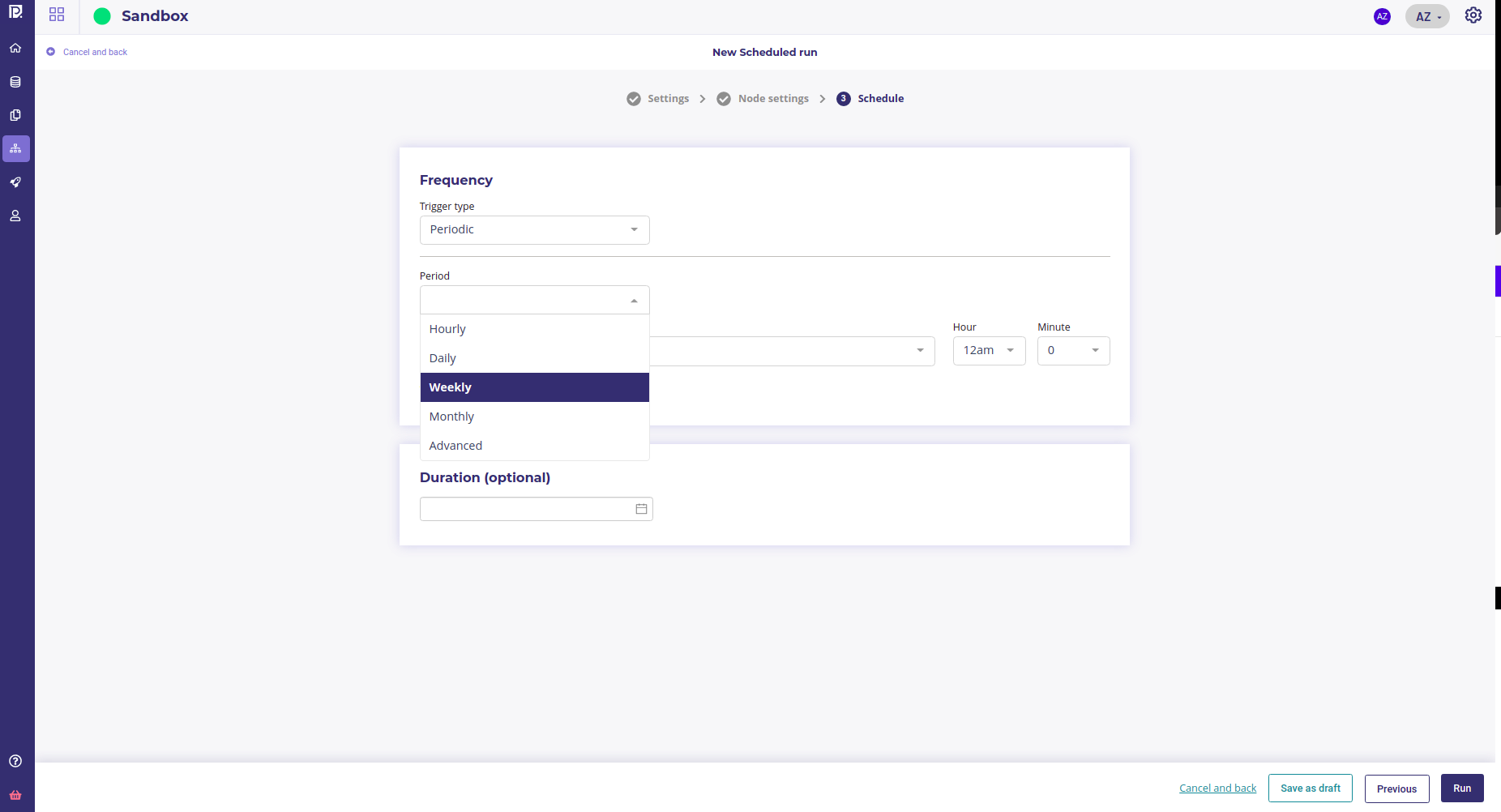
You can click on “next” and choose the Trigger type :
Manual : to run your pipeline once (useful for testing ). The pipeline will be run as soon as you click on run ( it can be run as much as you want later )
Periodic : to run your pipeline at a given period for some duration
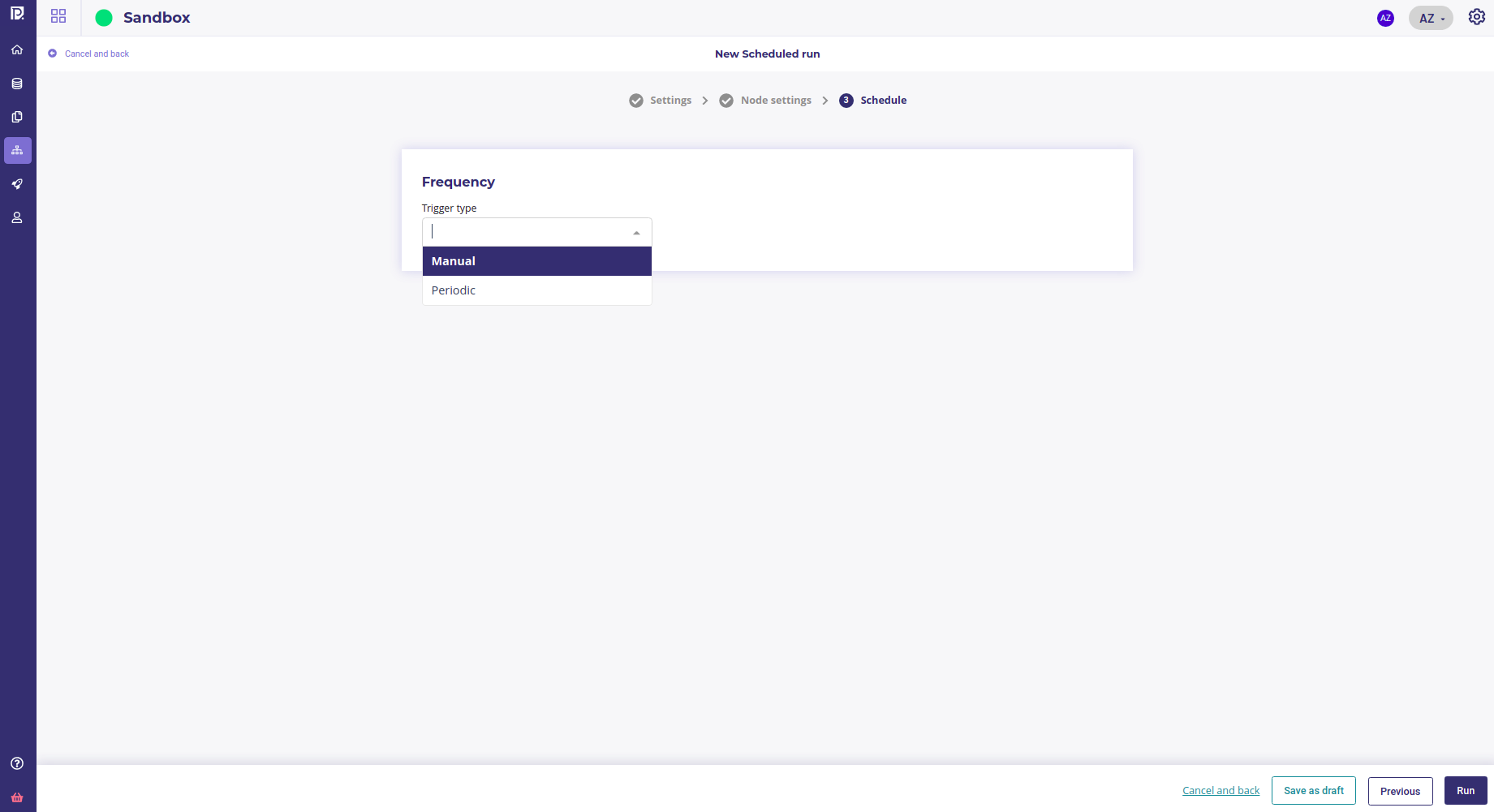
If you choose “periodic” you will be prompt to input some information :
hour ( and minutes ) for hourly run. The pipeline will be launch every day, every x hours. for Example, if you input 2 hours, the pipeline will be ran twelve time a day ( every 2 hours )
day period, hour and minutes of execution for daily run.
Note
Note that “Day” is the number of day between each run. If you input “5”,the pipeline will run every 5 days.
day of the week ( at least one ), hour and minut for a weekly period
months period, day, hour and minute for monthly period
a crontab expression ( see crontab guide for syntax ) if you select advanced mode
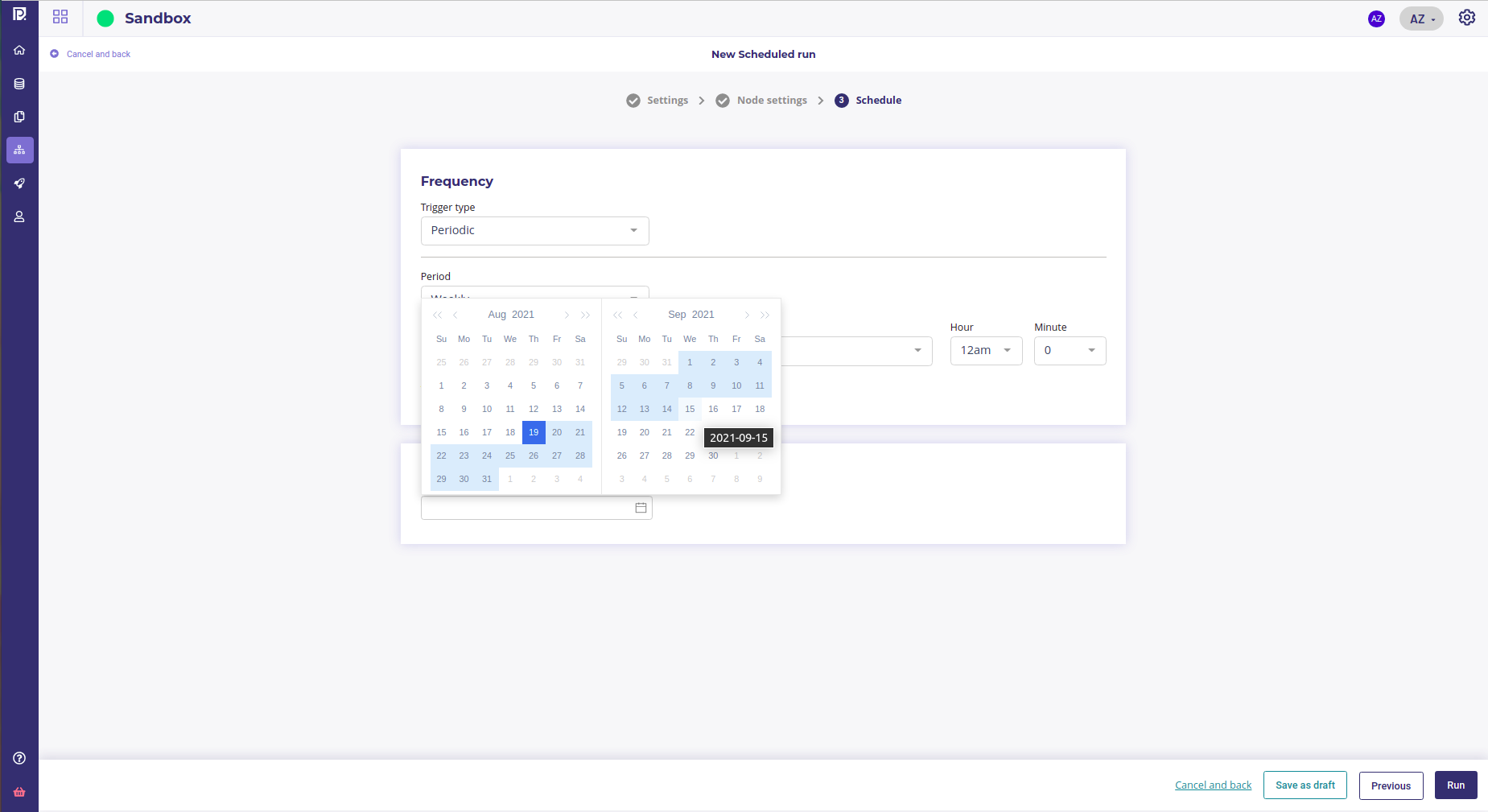
Once period input, you may select a start and end of run. The pipeline will only run on between the date you selected.
See all your scheduled run¶
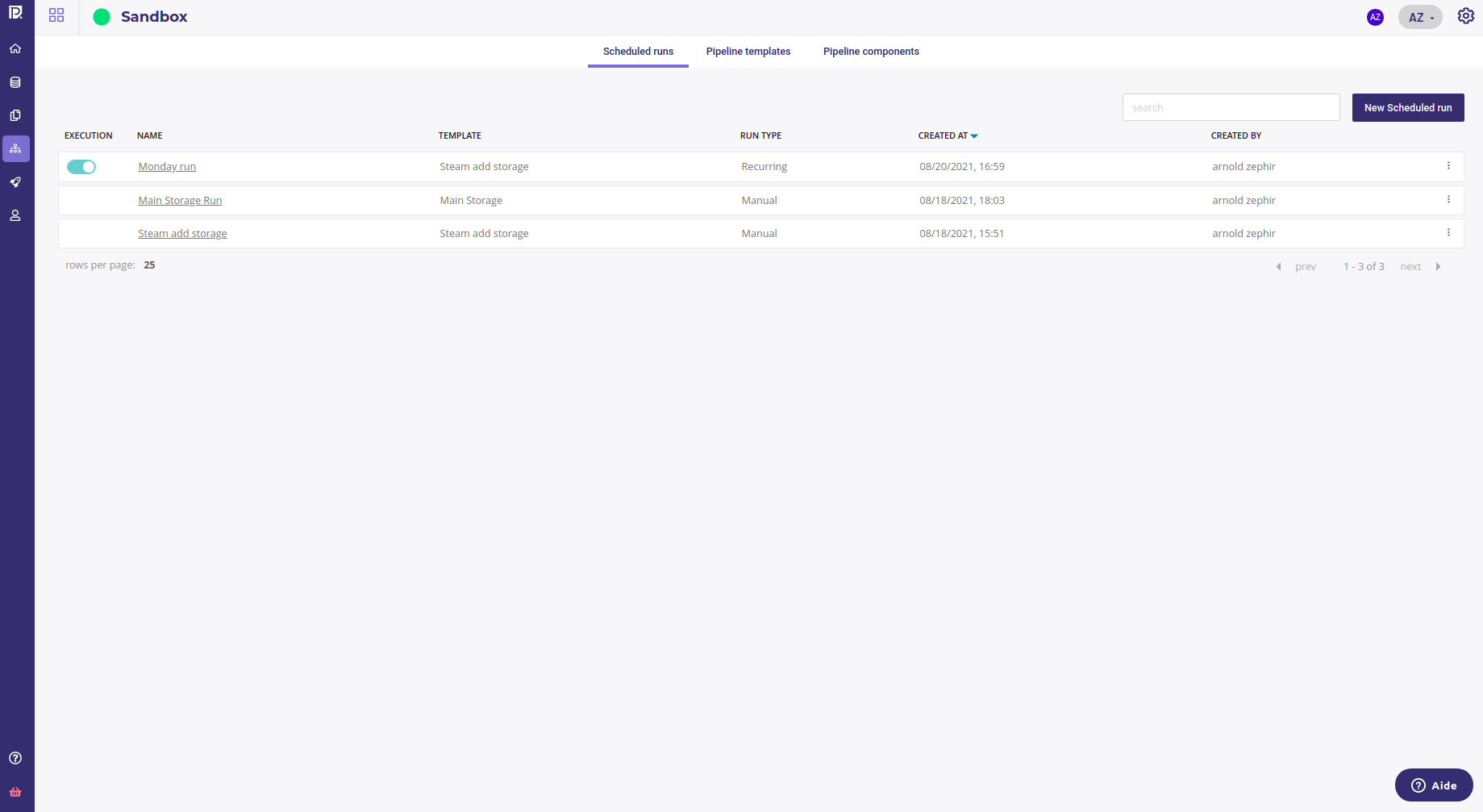
All your scheduled run are available under the Scheduled run tab ( in the pipeline section ) :
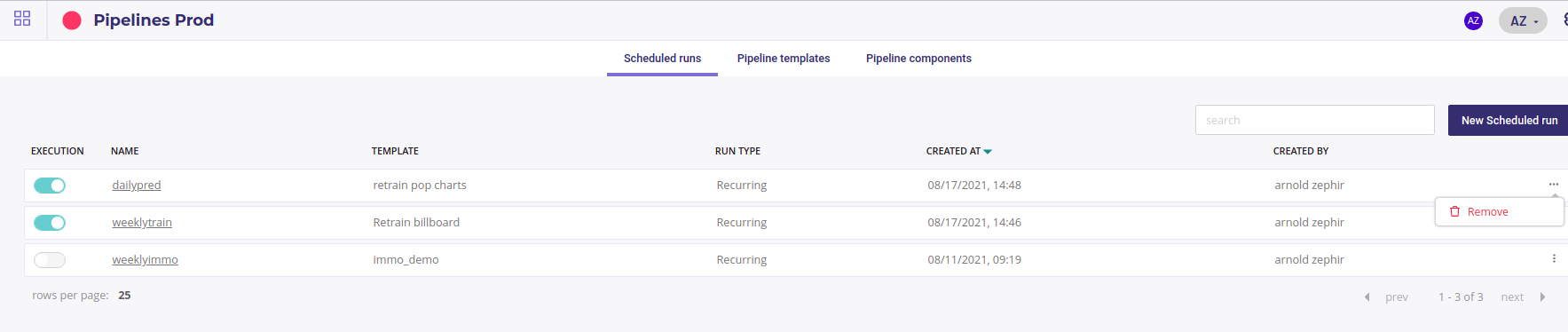
The scheduled run with a periodic schedule have a switch in order to disable or enable them. A disabled Run will obviously not run.
The “Manual” Scheduled run does not have Execution switch. Instead you need to trigger them manually.
See run state, trigger a run¶
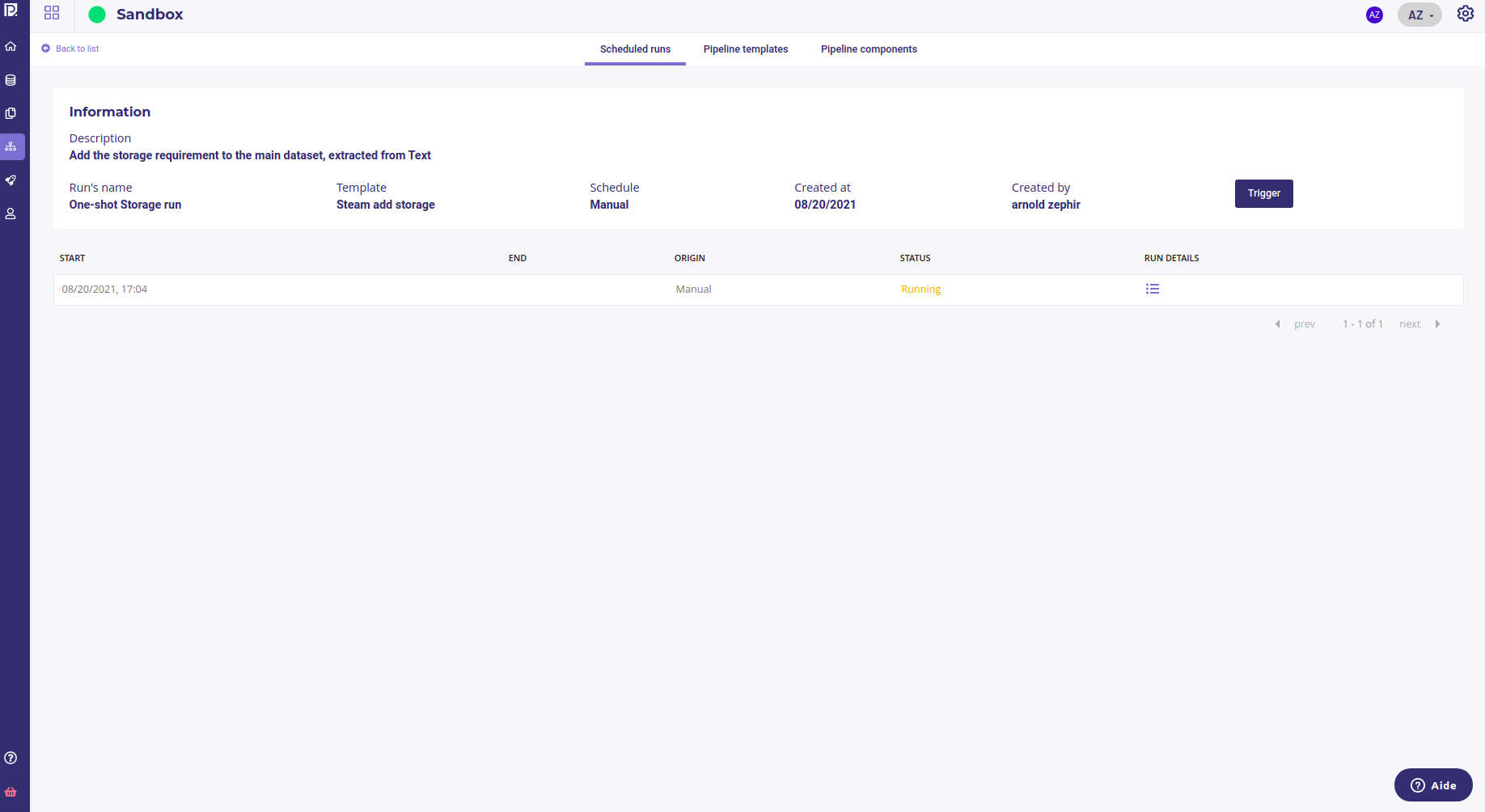
When clicking on a Scheduled Run in the list, you get details about its executions :
either previous executions, with a “done” status or a “failed” status
current execution status (“running”)
If an execution failed, you can get more informations by clicking on the “run detail” icon. For all execution that succeeded, the dataset produced are available in your “data” Section with the tag “pipeline output”
Each Scheduler Run can be trigger to run once and immediately by using the “Trigger” button.
Edit a run¶
You cannot edit a scheduled run, you have to create a new one.
Delete a Scheduled run¶
In the list of Scheduled Run , you can use the “More actions” icons to remove a scheduled run. Note that instead of removing it, you can disabled it by using the “execution” switch.